| Communication protocol | |
| Developer(s) | Vint Cerf and Bob Kahn |
|---|---|
| Introduction | 1974 |
| Based on | Transmission Control Program |
| OSI layer | 4 |
| RFC(s) | RFC 9293 |
The Transmission Control Protocol (TCP) is one of the main protocols of the Internet protocol suite. It originated in the initial network implementation in which it complemented the Internet Protocol (IP). Therefore, the entire suite is commonly referred to as TCP/IP. TCP provides reliable, ordered, and error-checked delivery of a stream of octets (bytes) between applications running on hosts communicating via an IP network. Major internet applications such as the World Wide Web, email, remote administration, and file transfer rely on TCP, which is part of the Transport Layer of the TCP/IP suite. SSL/TLS often runs on top of TCP.
TCP is connection-oriented, and a connection between client and server is established before data can be sent. The server must be listening (passive open) for connection requests from clients before a connection is established. Three-way handshake (active open), retransmission, and error detection adds to reliability but lengthens latency. Applications that do not require reliable data stream service may use the User Datagram Protocol (UDP) instead, which provides a connectionless datagram service that prioritizes time over reliability. TCP employs network congestion avoidance. However, there are vulnerabilities in TCP, including denial of service, connection hijacking, TCP veto, and reset attack.
Historical origin[edit]
In May 1974, Vint Cerf and Bob Kahn described an internetworking protocol for sharing resources using packet switching among network nodes.[1] The authors had been working with Gérard Le Lann to incorporate concepts from the French CYCLADES project into the new network.[2] The specification of the resulting protocol, RFC 675 (Specification of Internet Transmission Control Program), was written by Vint Cerf, Yogen Dalal, and Carl Sunshine, and published in December 1974. It contains the first attested use of the term internet, as a shorthand for internetwork.[3]
A central control component of this model was the Transmission Control Program that incorporated both connection-oriented links and datagram services between hosts. The monolithic Transmission Control Program was later divided into a modular architecture consisting of the Transmission Control Protocol and the Internet Protocol. This resulted in a networking model that became known informally as TCP/IP, although formally it was variously referred to as the Department of Defense (DOD) model, and ARPANET model, and eventually also as the Internet Protocol Suite.
In 2004, Vint Cerf and Bob Kahn received the Turing Award for their foundational work on TCP/IP.[4][5]
Network function[edit]
The Transmission Control Protocol provides a communication service at an intermediate level between an application program and the Internet Protocol. It provides host-to-host connectivity at the transport layer of the Internet model. An application does not need to know the particular mechanisms for sending data via a link to another host, such as the required IP fragmentation to accommodate the maximum transmission unit of the transmission medium. At the transport layer, TCP handles all handshaking and transmission details and presents an abstraction of the network connection to the application typically through a network socket interface.
At the lower levels of the protocol stack, due to network congestion, traffic load balancing, or unpredictable network behaviour, IP packets may be lost, duplicated, or delivered out of order. TCP detects these problems, requests re-transmission of lost data, rearranges out-of-order data and even helps minimize network congestion to reduce the occurrence of the other problems. If the data still remains undelivered, the source is notified of this failure. Once the TCP receiver has reassembled the sequence of octets originally transmitted, it passes them to the receiving application. Thus, TCP abstracts the application’s communication from the underlying networking details.
TCP is used extensively by many internet applications, including the World Wide Web (WWW), email, File Transfer Protocol, Secure Shell, peer-to-peer file sharing, and streaming media.
TCP is optimized for accurate delivery rather than timely delivery and can incur relatively long delays (on the order of seconds) while waiting for out-of-order messages or re-transmissions of lost messages. Therefore, it is not particularly suitable for real-time applications such as voice over IP. For such applications, protocols like the Real-time Transport Protocol (RTP) operating over the User Datagram Protocol (UDP) are usually recommended instead.[6]
TCP is a reliable byte stream delivery service which guarantees that all bytes received will be identical and in the same order as those sent. Since packet transfer by many networks is not reliable, TCP achieves this using a technique known as positive acknowledgement with re-transmission. This requires the receiver to respond with an acknowledgement message as it receives the data. The sender keeps a record of each packet it sends and maintains a timer from when the packet was sent. The sender re-transmits a packet if the timer expires before receiving the acknowledgement. The timer is needed in case a packet gets lost or corrupted.[6]
While IP handles actual delivery of the data, TCP keeps track of segments — the individual units of data transmission that a message is divided into for efficient routing through the network. For example, when an HTML file is sent from a web server, the TCP software layer of that server divides the file into segments and forwards them individually to the internet layer in the network stack. The internet layer software encapsulates each TCP segment into an IP packet by adding a header that includes (among other data) the destination IP address. When the client program on the destination computer receives them, the TCP software in the transport layer re-assembles the segments and ensures they are correctly ordered and error-free as it streams the file contents to the receiving application.
TCP segment structure[edit]
Transmission Control Protocol accepts data from a data stream, divides it into chunks, and adds a TCP header creating a TCP segment. The TCP segment is then encapsulated into an Internet Protocol (IP) datagram, and exchanged with peers.[7]
The term TCP packet appears in both informal and formal usage, whereas in more precise terminology segment refers to the TCP protocol data unit (PDU), datagram[8]: 5–6 to the IP PDU, and frame to the data link layer PDU:
Processes transmit data by calling on the TCP and passing buffers of data as arguments. The TCP packages the data from these buffers into segments and calls on the internet module [e.g. IP] to transmit each segment to the destination TCP.[9]
A TCP segment consists of a segment header and a data section. The segment header contains 10 mandatory fields, and an optional extension field (Options, pink background in table). The data section follows the header and is the payload data carried for the application. The length of the data section is not specified in the segment header; it can be calculated by subtracting the combined length of the segment header and IP header from the total IP datagram length specified in the IP header.
| Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octet | Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 0 | Source port | Destination port | ||||||||||||||||||||||||||||||
| 4 | 32 | Sequence number | |||||||||||||||||||||||||||||||
| 8 | 64 | Acknowledgment number (if ACK set) | |||||||||||||||||||||||||||||||
| 12 | 96 | Data offset | Reserved 0 0 0 | NS | CWR | ECE | URG | ACK | PSH | RST | SYN | FIN | Window Size | ||||||||||||||||||||
| 16 | 128 | Checksum | Urgent pointer (if URG set) | ||||||||||||||||||||||||||||||
| 20 | 160 | Options (if data offset > 5. Padded at the end with «0» bits if necessary.) | |||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
| 60 | 480 |
- Source port (16 bits)
- Identifies the sending port.
- Destination port (16 bits)
- Identifies the receiving port.
- Sequence number (32 bits)
- Has a dual role:
- If the SYN flag is set (1), then this is the initial sequence number. The sequence number of the actual first data byte and the acknowledged number in the corresponding ACK are then this sequence number plus 1.
- If the SYN flag is clear (0), then this is the accumulated sequence number of the first data byte of this segment for the current session.
- Acknowledgment number (32 bits)
- If the ACK flag is set then the value of this field is the next sequence number that the sender of the ACK is expecting. This acknowledges receipt of all prior bytes (if any). The first ACK sent by each end acknowledges the other end’s initial sequence number itself, but no data.
- Data offset (4 bits)
- Specifies the size of the TCP header in 32-bit words. The minimum size header is 5 words and the maximum is 15 words thus giving the minimum size of 20 bytes and maximum of 60 bytes, allowing for up to 40 bytes of options in the header. This field gets its name from the fact that it is also the offset from the start of the TCP segment to the actual data.
- Reserved (3 bits)
- For future use and should be set to zero.
- Flags (9 bits)
- Contains 9 1-bit flags (control bits) as follows:
- NS (1 bit): ECN-nonce — concealment protection[a]
- CWR (1 bit): Congestion window reduced (CWR) flag is set by the sending host to indicate that it received a TCP segment with the ECE flag set and had responded in congestion control mechanism.[b]
- ECE (1 bit): ECN-Echo has a dual role, depending on the value of the SYN flag. It indicates:
-
- If the SYN flag is set (1), that the TCP peer is ECN capable.
- If the SYN flag is clear (0), that a packet with Congestion Experienced flag set (ECN=11) in the IP header was received during normal transmission.[b] This serves as an indication of network congestion (or impending congestion) to the TCP sender.
- URG (1 bit): Indicates that the Urgent pointer field is significant
- ACK (1 bit): Indicates that the Acknowledgment field is significant. All packets after the initial SYN packet sent by the client should have this flag set.
- PSH (1 bit): Push function. Asks to push the buffered data to the receiving application.
- RST (1 bit): Reset the connection
- SYN (1 bit): Synchronize sequence numbers. Only the first packet sent from each end should have this flag set. Some other flags and fields change meaning based on this flag, and some are only valid when it is set, and others when it is clear.
- FIN (1 bit): Last packet from sender
- Window size (16 bits)
- The size of the receive window, which specifies the number of window size units[c] that the sender of this segment is currently willing to receive.[d] (See § Flow control and § Window scaling.)
- Checksum (16 bits)
- The 16-bit checksum field is used for error-checking of the TCP header, the payload and an IP pseudo-header. The pseudo-header consists of the source IP address, the destination IP address, the protocol number for the TCP protocol (6) and the length of the TCP headers and payload (in bytes).
- Urgent pointer (16 bits)
- If the URG flag is set, then this 16-bit field is an offset from the sequence number indicating the last urgent data byte.
- Options (Variable 0–320 bits, in units of 32 bits)
- The length of this field is determined by the data offset field. Options have up to three fields: Option-Kind (1 byte), Option-Length (1 byte), Option-Data (variable). The Option-Kind field indicates the type of option and is the only field that is not optional. Depending on Option-Kind value, the next two fields may be set. Option-Length indicates the total length of the option, and Option-Data contains data associated with the option, if applicable. For example, an Option-Kind byte of 1 indicates that this is a no operation option used only for padding, and does not have an Option-Length or Option-Data fields following it. An Option-Kind byte of 0 marks the end of options, and is also only one byte. An Option-Kind byte of 2 is used to indicate Maximum Segment Size option, and will be followed by an Option-Length byte specifying the length of the MSS field. Option-Length is the total length of the given options field, including Option-Kind and Option-Length fields. So while the MSS value is typically expressed in two bytes, Option-Length will be 4. As an example, an MSS option field with a value of 0x05B4 is coded as (0x02 0x04 0x05B4) in the TCP options section.
- Some options may only be sent when SYN is set; they are indicated below as
[SYN]. Option-Kind and standard lengths given as (Option-Kind, Option-Length).
-
Option-Kind Option-Length Option-Data Purpose Notes 0 — — End of options list 1 — — No operation This may be used to align option fields on 32-bit boundaries for better performance. 2 4 SS Maximum segment size See § Maximum segment size [SYN]3 3 S Window scale See § Window scaling for details[10] [SYN]4 2 — Selective Acknowledgement permitted See § Selective acknowledgments for details[11]: §2 [SYN]5 N (10, 18, 26, or 34) BBBB, EEEE, … Selective ACKnowledgement (SACK)[11]: §3 These first two bytes are followed by a list of 1–4 blocks being selectively acknowledged, specified as 32-bit begin/end pointers. 8 10 TTTT, EEEE Timestamp and echo of previous timestamp See § TCP timestamps for details[12]
- The remaining Option-Kind values are historical, obsolete, experimental, not yet standardized, or unassigned. Option number assignments are maintained by the IANA.[13]
- Padding
- The TCP header padding is used to ensure that the TCP header ends, and data begins, on a 32-bit boundary. The padding is composed of zeros.[9]
Protocol operation[edit]
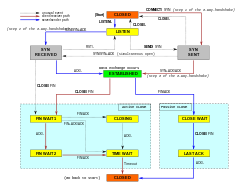
A Simplified TCP State Diagram. See TCP EFSM diagram for more detailed diagrams, including detail on the ESTABLISHED state.
TCP protocol operations may be divided into three phases. Connection establishment is a multi-step handshake process that establishes a connection before entering the data transfer phase. After data transfer is completed, the connection termination closes the connection and releases all allocated resources.
A TCP connection is managed by an operating system through a resource that represents the local end-point for communications, the Internet socket. During the lifetime of a TCP connection, the local end-point undergoes a series of state changes:[14]
| State | Endpoint | Description |
|---|---|---|
| LISTEN | Server | Waiting for a connection request from any remote TCP end-point. |
| SYN-SENT | Client | Waiting for a matching connection request after having sent a connection request. |
| SYN-RECEIVED | Server | Waiting for a confirming connection request acknowledgment after having both received and sent a connection request. |
| ESTABLISHED | Server and client | An open connection, data received can be delivered to the user. The normal state for the data transfer phase of the connection. |
| FIN-WAIT-1 | Server and client | Waiting for a connection termination request from the remote TCP, or an acknowledgment of the connection termination request previously sent. |
| FIN-WAIT-2 | Server and client | Waiting for a connection termination request from the remote TCP. |
| CLOSE-WAIT | Server and client | Waiting for a connection termination request from the local user. |
| CLOSING | Server and client | Waiting for a connection termination request acknowledgment from the remote TCP. |
| LAST-ACK | Server and client | Waiting for an acknowledgment of the connection termination request previously sent to the remote TCP (which includes an acknowledgment of its connection termination request). |
| TIME-WAIT | Server or client | Waiting for enough time to pass to be sure that all remaining packets on the connection have expired. |
| CLOSED | Server and client | No connection state at all. |
Connection establishment[edit]
Before a client attempts to connect with a server, the server must first bind to and listen at a port to open it up for connections: this is called a passive open. Once the passive open is established, a client may establish a connection by initiating an active open using the three-way (or 3-step) handshake:
- SYN: The active open is performed by the client sending a SYN to the server. The client sets the segment’s sequence number to a random value A.
- SYN-ACK: In response, the server replies with a SYN-ACK. The acknowledgment number is set to one more than the received sequence number i.e. A+1, and the sequence number that the server chooses for the packet is another random number, B.
- ACK: Finally, the client sends an ACK back to the server. The sequence number is set to the received acknowledgment value i.e. A+1, and the acknowledgment number is set to one more than the received sequence number i.e. B+1.
Steps 1 and 2 establish and acknowledge the sequence number for one direction. Steps 2 and 3 establish and acknowledge the sequence number for the other direction. Following the completion of these steps, both the client and server have received acknowledgments and a full-duplex communication is established.
Connection termination[edit]

The connection termination phase uses a four-way handshake, with each side of the connection terminating independently. When an endpoint wishes to stop its half of the connection, it transmits a FIN packet, which the other end acknowledges with an ACK. Therefore, a typical tear-down requires a pair of FIN and ACK segments from each TCP endpoint. After the side that sent the first FIN has responded with the final ACK, it waits for a timeout before finally closing the connection, during which time the local port is unavailable for new connections; this state lets the TCP client resend the final acknowledgement to the server in case the ACK is lost in transit. The time duration is implementation-dependent, but some common values are 30 seconds, 1 minute, and 2 minutes. After the timeout, the client enters the CLOSED state and the local port becomes available for new connections.[15]
It is also possible to terminate the connection by a 3-way handshake, when host A sends a FIN and host B replies with a FIN & ACK (combining two steps into one) and host A replies with an ACK.[16]
Some operating systems, such as Linux and HP-UX,[citation needed] implement a half-duplex close sequence. If the host actively closes a connection, while still having unread incoming data available, the host sends the signal RST (losing any received data) instead of FIN. This assures that a TCP application is aware there was a data loss.[17]
A connection can be in a half-open state, in which case one side has terminated the connection, but the other has not. The side that has terminated can no longer send any data into the connection, but the other side can. The terminating side should continue reading the data until the other side terminates as well.[citation needed]
Resource usage[edit]
Most implementations allocate an entry in a table that maps a session to a running operating system process. Because TCP packets do not include a session identifier, both endpoints identify the session using the client’s address and port. Whenever a packet is received, the TCP implementation must perform a lookup on this table to find the destination process. Each entry in the table is known as a Transmission Control Block or TCB. It contains information about the endpoints (IP and port), status of the connection, running data about the packets that are being exchanged and buffers for sending and receiving data.
The number of sessions in the server side is limited only by memory and can grow as new connections arrive, but the client must allocate an ephemeral port before sending the first SYN to the server. This port remains allocated during the whole conversation and effectively limits the number of outgoing connections from each of the client’s IP addresses. If an application fails to properly close unrequired connections, a client can run out of resources and become unable to establish new TCP connections, even from other applications.
Both endpoints must also allocate space for unacknowledged packets and received (but unread) data.
Data transfer[edit]
The Transmission Control Protocol differs in several key features compared to the User Datagram Protocol:
- Ordered data transfer: the destination host rearranges segments according to a sequence number[6]
- Retransmission of lost packets: any cumulative stream not acknowledged is retransmitted[6]
- Error-free data transfer: corrupted packets are treated as lost and are retransmitted[18]
- Flow control: limits the rate a sender transfers data to guarantee reliable delivery. The receiver continually hints the sender on how much data can be received. When the receiving host’s buffer fills, the next acknowledgment suspends the transfer and allows the data in the buffer to be processed.[6]
- Congestion control: lost packets (presumed due to congestion) trigger a reduction in data delivery rate[6]
Reliable transmission[edit]
TCP uses a sequence number to identify each byte of data. The sequence number identifies the order of the bytes sent from each computer so that the data can be reconstructed in order, regardless of any out-of-order delivery that may occur. The sequence number of the first byte is chosen by the transmitter for the first packet, which is flagged SYN. This number can be arbitrary, and should, in fact, be unpredictable to defend against TCP sequence prediction attacks.
Acknowledgements (ACKs) are sent with a sequence number by the receiver of data to tell the sender that data has been received to the specified byte. ACKs do not imply that the data has been delivered to the application, they merely signify that it is now the receiver’s responsibility to deliver the data.
Reliability is achieved by the sender detecting lost data and retransmitting it. TCP uses two primary techniques to identify loss. Retransmission timeout (RTO) and duplicate cumulative acknowledgements (DupAcks).
Dupack-based retransmission[edit]
If a single segment (say segment number 100) in a stream is lost, then the receiver cannot acknowledge packets above that segment number (100) because it uses cumulative ACKs. Hence the receiver acknowledges packet 99 again on the receipt of another data packet. This duplicate acknowledgement is used as a signal for packet loss. That is, if the sender receives three duplicate acknowledgements, it retransmits the last unacknowledged packet. A threshold of three is used because the network may reorder segments causing duplicate acknowledgements. This threshold has been demonstrated to avoid spurious retransmissions due to reordering.[19] Some TCP implementation use selective acknowledgements (SACKs) to provide explicit feedback about the segments that have been received. This greatly improves TCP’s ability to retransmit the right segments.
Timeout-based retransmission[edit]
When a sender transmits a segment, it initializes a timer with a conservative estimate of the arrival time of the acknowledgement. The segment is retransmitted if the timer expires, with a new timeout threshold of twice the previous value, resulting in exponential backoff behavior. Typically, the initial timer value is 

Error detection[edit]
Sequence numbers allow receivers to discard duplicate packets and properly sequence out-of-order packets. Acknowledgments allow senders to determine when to retransmit lost packets.
To assure correctness a checksum field is included; see § Checksum computation for details. The TCP checksum is a weak check by modern standards and is normally paired with a CRC integrity check at layer 2, below both TCP and IP, such as is used in PPP or the Ethernet frame. However, introduction of errors in packets between CRC-protected hops is common and the 16-bit TCP checksum catches most of these.[21]
Flow control[edit]
TCP uses an end-to-end flow control protocol to avoid having the sender send data too fast for the TCP receiver to receive and process it reliably. Having a mechanism for flow control is essential in an environment where machines of diverse network speeds communicate. For example, if a PC sends data to a smartphone that is slowly processing received data, the smartphone must be able to regulate the data flow so as not to be overwhelmed.[6]
TCP uses a sliding window flow control protocol. In each TCP segment, the receiver specifies in the receive window field the amount of additionally received data (in bytes) that it is willing to buffer for the connection. The sending host can send only up to that amount of data before it must wait for an acknowledgement and receive window update from the receiving host.

TCP sequence numbers and receive windows behave very much like a clock. The receive window shifts each time the receiver receives and acknowledges a new segment of data. Once it runs out of sequence numbers, the sequence number loops back to 0.
When a receiver advertises a window size of 0, the sender stops sending data and starts its persist timer. The persist timer is used to protect TCP from a deadlock situation that could arise if a subsequent window size update from the receiver is lost, and the sender cannot send more data until receiving a new window size update from the receiver. When the persist timer expires, the TCP sender attempts recovery by sending a small packet so that the receiver responds by sending another acknowledgement containing the new window size.
If a receiver is processing incoming data in small increments, it may repeatedly advertise a small receive window. This is referred to as the silly window syndrome, since it is inefficient to send only a few bytes of data in a TCP segment, given the relatively large overhead of the TCP header.
Congestion control[edit]
The final main aspect of TCP is congestion control. TCP uses a number of mechanisms to achieve high performance and avoid congestive collapse, a gridlock situation where network performance is severely degraded. These mechanisms control the rate of data entering the network, keeping the data flow below a rate that would trigger collapse. They also yield an approximately max-min fair allocation between flows.
Acknowledgments for data sent, or the lack of acknowledgments, are used by senders to infer network conditions between the TCP sender and receiver. Coupled with timers, TCP senders and receivers can alter the behavior of the flow of data. This is more generally referred to as congestion control or congestion avoidance.
Modern implementations of TCP contain four intertwined algorithms: slow start, congestion avoidance, fast retransmit, and fast recovery.[22]
In addition, senders employ a retransmission timeout (RTO) that is based on the estimated round-trip time (RTT) between the sender and receiver, as well as the variance in this round-trip time.[20] There are subtleties in the estimation of RTT. For example, senders must be careful when calculating RTT samples for retransmitted packets; typically they use Karn’s Algorithm or TCP timestamps.[23] These individual RTT samples are then averaged over time to create a smoothed round trip time (SRTT) using Jacobson’s algorithm. This SRTT value is what is used as the round-trip time estimate.
Enhancing TCP to reliably handle loss, minimize errors, manage congestion and go fast in very high-speed environments are ongoing areas of research and standards development. As a result, there are a number of TCP congestion avoidance algorithm variations.
Maximum segment size[edit]
The maximum segment size (MSS) is the largest amount of data, specified in bytes, that TCP is willing to receive in a single segment. For best performance, the MSS should be set small enough to avoid IP fragmentation, which can lead to packet loss and excessive retransmissions. To accomplish this, typically the MSS is announced by each side using the MSS option when the TCP connection is established. The option value is derived from the maximum transmission unit (MTU) size of the data link layer of the networks to which the sender and receiver are directly attached. TCP senders can use path MTU discovery to infer the minimum MTU along the network path between the sender and receiver, and use this to dynamically adjust the MSS to avoid IP fragmentation within the network.
MSS announcement may also be called MSS negotiation but, strictly speaking, the MSS is not negotiated. Two completely independent values of MSS are permitted for the two directions of data flow in a TCP connection,[24][9] so there is no need to agree on a common MSS configuration for a bidirectional connection.
Selective acknowledgments[edit]
Relying purely on the cumulative acknowledgment scheme employed by the original TCP can lead to inefficiencies when packets are lost. For example, suppose bytes with sequence number 1,000 to 10,999 are sent in 10 different TCP segments of equal size, and the second segment (sequence numbers 2,000 to 2,999) is lost during transmission. In a pure cumulative acknowledgment protocol, the receiver can only send a cumulative ACK value of 2,000 (the sequence number immediately following the last sequence number of the received data) and cannot say that it received bytes 3,000 to 10,999 successfully. Thus the sender may then have to resend all data starting with sequence number 2,000.
To alleviate this issue TCP employs the selective acknowledgment (SACK) option, defined in 1996 in RFC 2018, which allows the receiver to acknowledge discontinuous blocks of packets that were received correctly, in addition to the sequence number immediately following the last sequence number of the last contiguous byte received successively, as in the basic TCP acknowledgment. The acknowledgment can include a number of SACK blocks, where each SACK block is conveyed by the Left Edge of Block (the first sequence number of the block) and the Right Edge of Block (the sequence number immediately following the last sequence number of the block), with a Block being a contiguous range that the receiver correctly received. In the example above, the receiver would send an ACK segment with a cumulative ACK value of 2,000 and a SACK option header with sequence numbers 3,000 and 11,000. The sender would accordingly retransmit only the second segment with sequence numbers 2,000 to 2,999.
A TCP sender may interpret an out-of-order segment delivery as a lost segment. If it does so, the TCP sender will retransmit the segment previous to the out-of-order packet and slow its data delivery rate for that connection. The duplicate-SACK option, an extension to the SACK option that was defined in May 2000 in RFC 2883, solves this problem. The TCP receiver sends a D-ACK to indicate that no segments were lost, and the TCP sender can then reinstate the higher transmission rate.
The SACK option is not mandatory and comes into operation only if both parties support it. This is negotiated when a connection is established. SACK uses a TCP header option (see § TCP segment structure for details). The use of SACK has become widespread—all popular TCP stacks support it. Selective acknowledgment is also used in Stream Control Transmission Protocol (SCTP).
Window scaling[edit]
For more efficient use of high-bandwidth networks, a larger TCP window size may be used. A 16-bit TCP window size field controls the flow of data and its value is limited to 65,535 bytes. Since the size field cannot be expanded beyond this limit, a scaling factor is used. The TCP window scale option, as defined in RFC 1323, is an option used to increase the maximum window size to 1 gigabyte. Scaling up to these larger window sizes is necessary for TCP tuning.
The window scale option is used only during the TCP 3-way handshake. The window scale value represents the number of bits to left-shift the 16-bit window size field when interpreting it. The window scale value can be set from 0 (no shift) to 14 for each direction independently. Both sides must send the option in their SYN segments to enable window scaling in either direction.
Some routers and packet firewalls rewrite the window scaling factor during a transmission. This causes sending and receiving sides to assume different TCP window sizes. The result is non-stable traffic that may be very slow. The problem is visible on some sites behind a defective router.[25]
TCP timestamps[edit]
TCP timestamps, defined in RFC 1323 in 1992, can help TCP determine in which order packets were sent. TCP timestamps are not normally aligned to the system clock and start at some random value. Many operating systems will increment the timestamp for every elapsed millisecond; however, the RFC only states that the ticks should be proportional.
There are two timestamp fields:
- a 4-byte sender timestamp value (my timestamp)
- a 4-byte echo reply timestamp value (the most recent timestamp received from you).
TCP timestamps are used in an algorithm known as Protection Against Wrapped Sequence numbers, or PAWS. PAWS is used when the receive window crosses the sequence number wraparound boundary. In the case where a packet was potentially retransmitted, it answers the question: «Is this sequence number in the first 4 GB or the second?» And the timestamp is used to break the tie.
Also, the Eifel detection algorithm uses TCP timestamps to determine if retransmissions are occurring because packets are lost or simply out of order.[26]
TCP timestamps are enabled by default in Linux,[27] and disabled by default in Windows Server 2008, 2012 and 2016.[28]
Recent Statistics show that the level of TCP timestamp adoption has stagnated, at ~40%, owing to Windows Server dropping support since Windows Server 2008.[29]
Out-of-band data[edit]
It is possible to interrupt or abort the queued stream instead of waiting for the stream to finish. This is done by specifying the data as urgent. This marks the transmission as out-of-band data (OOB) and tells the receiving program to process it immediately. When finished, TCP informs the application and resumes the stream queue. An example is when TCP is used for a remote login session where the user can send a keyboard sequence that interrupts or aborts the remotely-running program without waiting for the program to finish its current transfer.[6]
The urgent pointer only alters the processing on the remote host and doesn’t expedite any processing on the network itself. The capability is implemented differently or poorly on different systems or may not be supported. Where it is available, it is prudent to assume only single bytes of OOB data will be reliably handled.[30][31] Since the feature is not frequently used, it is not well tested on some platforms and has been associated with vunerabilities, WinNuke for instance.
Forcing data delivery[edit]
Normally, TCP waits for 200 ms for a full packet of data to send (Nagle’s Algorithm tries to group small messages into a single packet). This wait creates small, but potentially serious delays if repeated constantly during a file transfer. For example, a typical send block would be 4 KB, a typical MSS is 1460, so 2 packets go out on a 10 Mbit/s ethernet taking ~1.2 ms each followed by a third carrying the remaining 1176 after a 197 ms pause because TCP is waiting for a full buffer.
In the case of telnet, each user keystroke is echoed back by the server before the user can see it on the screen. This delay would become very annoying.
Setting the socket option TCP_NODELAY overrides the default 200 ms send delay. Application programs use this socket option to force output to be sent after writing a character or line of characters.
The RFC defines the PSH push bit as «a message to the receiving TCP stack to send this data immediately up to the receiving application».[6] There is no way to indicate or control it in user space using Berkeley sockets and it is controlled by protocol stack only.[32]
Vulnerabilities[edit]
TCP may be attacked in a variety of ways. The results of a thorough security assessment of TCP, along with possible mitigations for the identified issues, were published in 2009,[33] and is currently[when?] being pursued within the IETF.[34]
Denial of service[edit]
By using a spoofed IP address and repeatedly sending purposely assembled SYN packets, followed by many ACK packets, attackers can cause the server to consume large amounts of resources keeping track of the bogus connections. This is known as a SYN flood attack. Proposed solutions to this problem include SYN cookies and cryptographic puzzles, though SYN cookies come with their own set of vulnerabilities.[35] Sockstress is a similar attack, that might be mitigated with system resource management.[36] An advanced DoS attack involving the exploitation of the TCP Persist Timer was analyzed in Phrack #66.[37] PUSH and ACK floods are other variants.[38]
Connection hijacking[edit]
An attacker who is able to eavesdrop a TCP session and redirect packets can hijack a TCP connection. To do so, the attacker learns the sequence number from the ongoing communication and forges a false segment that looks like the next segment in the stream. Such a simple hijack can result in one packet being erroneously accepted at one end. When the receiving host acknowledges the extra segment to the other side of the connection, synchronization is lost. Hijacking might be combined with Address Resolution Protocol (ARP) or routing attacks that allow taking control of the packet flow, so as to get permanent control of the hijacked TCP connection.[39]
Impersonating a different IP address was not difficult prior to RFC 1948, when the initial sequence number was easily guessable. That allowed an attacker to blindly send a sequence of packets that the receiver would believe to come from a different IP address, without the need to deploy ARP or routing attacks: it is enough to ensure that the legitimate host of the impersonated IP address is down, or bring it to that condition using denial-of-service attacks. This is why the initial sequence number is now chosen at random.
TCP veto[edit]
An attacker who can eavesdrop and predict the size of the next packet to be sent can cause the receiver to accept a malicious payload without disrupting the existing connection. The attacker injects a malicious packet with the sequence number and a payload size of the next expected packet. When the legitimate packet is ultimately received, it is found to have the same sequence number and length as a packet already received and is silently dropped as a normal duplicate packet—the legitimate packet is «vetoed» by the malicious packet. Unlike in connection hijacking, the connection is never desynchronized and communication continues as normal after the malicious payload is accepted. TCP veto gives the attacker less control over the communication, but makes the attack particularly resistant to detection. The large increase in network traffic from the ACK storm is avoided. The only evidence to the receiver that something is amiss is a single duplicate packet, a normal occurrence in an IP network. The sender of the vetoed packet never sees any evidence of an attack.[40]
Another vulnerability is the TCP reset attack.
TCP ports[edit]
TCP and UDP use port numbers to identify sending and receiving application end-points on a host, often called Internet sockets. Each side of a TCP connection has an associated 16-bit unsigned port number (0-65535) reserved by the sending or receiving application. Arriving TCP packets are identified as belonging to a specific TCP connection by its sockets, that is, the combination of source host address, source port, destination host address, and destination port. This means that a server computer can provide several clients with several services simultaneously, as long as a client takes care of initiating any simultaneous connections to one destination port from different source ports.
Port numbers are categorized into three basic categories: well-known, registered, and dynamic/private. The well-known ports are assigned by the Internet Assigned Numbers Authority (IANA) and are typically used by system-level or root processes. Well-known applications running as servers and passively listening for connections typically use these ports. Some examples include: FTP (20 and 21), SSH (22), TELNET (23), SMTP (25), HTTP over SSL/TLS (443), and HTTP (80). Note, as of the latest standard, HTTP/3, QUIC is used as a transport instead of TCP. Registered ports are typically used by end user applications as ephemeral source ports when contacting servers, but they can also identify named services that have been registered by a third party. Dynamic/private ports can also be used by end user applications, but are less commonly so. Dynamic/private ports do not contain any meaning outside of any particular TCP connection.
Network Address Translation (NAT), typically uses dynamic port numbers, on the («Internet-facing») public side, to disambiguate the flow of traffic that is passing between a public network and a private subnetwork, thereby allowing many IP addresses (and their ports) on the subnet to be serviced by a single public-facing address.
Development[edit]
TCP is a complex protocol. However, while significant enhancements have been made and proposed over the years, its most basic operation has not changed significantly since its first specification RFC 675 in 1974, and the v4 specification RFC 793, published in September 1981. RFC 1122, Host Requirements for Internet Hosts, clarified a number of TCP protocol implementation requirements. A list of the 8 required specifications and over 20 strongly encouraged enhancements is available in RFC 7414. Among this list is RFC 2581, TCP Congestion Control, one of the most important TCP-related RFCs in recent years, describes updated algorithms that avoid undue congestion. In 2001, RFC 3168 was written to describe Explicit Congestion Notification (ECN), a congestion avoidance signaling mechanism.
The original TCP congestion avoidance algorithm was known as «TCP Tahoe», but many alternative algorithms have since been proposed (including TCP Reno, TCP Vegas, FAST TCP, TCP New Reno, and TCP Hybla).
TCP Interactive (iTCP) [41] is a research effort into TCP extensions that allows applications to subscribe to TCP events and register handler components that can launch applications for various purposes, including application-assisted congestion control.
Multipath TCP (MPTCP) [42][43] is an ongoing effort within the IETF that aims at allowing a TCP connection to use multiple paths to maximize resource usage and increase redundancy. The redundancy offered by Multipath TCP in the context of wireless networks enables the simultaneous utilization of different networks, which brings higher throughput and better handover capabilities. Multipath TCP also brings performance benefits in datacenter environments.[44] The reference implementation[45] of Multipath TCP is being developed in the Linux kernel.[46] Multipath TCP is used to support the Siri voice recognition application on iPhones, iPads and Macs [47]
tcpcrypt is an extension proposed in July 2010 to provide transport-level encryption directly in TCP itself. It is designed to work transparently and not require any configuration. Unlike TLS (SSL), tcpcrypt itself does not provide authentication, but provides simple primitives down to the application to do that. As of 2010, the first tcpcrypt IETF draft has been published and implementations exist for several major platforms.
TCP Fast Open is an extension to speed up the opening of successive TCP connections between two endpoints. It works by skipping the three-way handshake using a cryptographic «cookie». It is similar to an earlier proposal called T/TCP, which was not widely adopted due to security issues.[48] TCP Fast Open was published as RFC 7413 in 2014.[49]
Proposed in May 2013, Proportional Rate Reduction (PRR) is a TCP extension developed by Google engineers. PRR ensures that the TCP window size after recovery is as close to the slow start threshold as possible.[50] The algorithm is designed to improve the speed of recovery and is the default congestion control algorithm in Linux 3.2+ kernels.[51]
Deprecated proposals[edit]
TCP Cookie Transactions (TCPCT) is an extension proposed in December 2009[52] to secure servers against denial-of-service attacks. Unlike SYN cookies, TCPCT does not conflict with other TCP extensions such as window scaling. TCPCT was designed due to necessities of DNSSEC, where servers have to handle large numbers of short-lived TCP connections. In 2016, TCPCT was deprecated in favor of TCP Fast Open. Status of the original RFC was changed to «historic».[53]
TCP over wireless networks[edit]
TCP was originally designed for wired networks. Packet loss is considered to be the result of network congestion and the congestion window size is reduced dramatically as a precaution. However, wireless links are known to experience sporadic and usually temporary losses due to fading, shadowing, hand off, interference, and other radio effects, that are not strictly congestion. After the (erroneous) back-off of the congestion window size, due to wireless packet loss, there may be a congestion avoidance phase with a conservative decrease in window size. This causes the radio link to be underutilized. Extensive research on combating these harmful effects has been conducted. Suggested solutions can be categorized as end-to-end solutions, which require modifications at the client or server,[54] link layer solutions, such as Radio Link Protocol (RLP) in cellular networks, or proxy-based solutions which require some changes in the network without modifying end nodes.[54][55]
A number of alternative congestion control algorithms, such as Vegas, Westwood, Veno, and Santa Cruz, have been proposed to help solve the wireless problem.[citation needed]
Hardware implementations[edit]
One way to overcome the processing power requirements of TCP is to build hardware implementations of it, widely known as TCP offload engines (TOE). The main problem of TOEs is that they are hard to integrate into computing systems, requiring extensive changes in the operating system of the computer or device. One company to develop such a device was Alacritech.
Wire image and ossification[edit]
The wire image of TCP provides significant information-gathering and modification opportunities to on-path observers, as the protocol metadata is transmitted in cleartext.[56][57] While this transparency is useful to network operators and researchers,[59] information gathered from protocol metadata may reduce the end-user’s privacy.[60] This visibility and malleability of metadata has led to TCP being difficult to extend—a case of protocol ossification—as any intermediate node (a ‘middlebox’) can make decisions based on that metadata or even modify it,[61][62] breaking the end-to-end principle.[63] One measurement found that a third of paths across the Internet encounter at least one intermediary that modifies TCP metadata, and 6.5% of paths encounter harmful ossifying effects from intermediaries.[64] Avoiding extensibility hazards from intermediaries placed significant constraints on the design of MPTCP,[65][66] and difficulties caused by intermediaries have hindered the deployment of TCP Fast Open in web browsers.[67] Another source of ossification is the difficulty of modification of TCP functions at the endpoints, typically in the operating system kernel[68] or in hardware with a TCP offload engine.[69]
Performance[edit]
As TCP provides applications with the abstraction of a reliable byte stream, it can suffer from head-of-line blocking: if packets are reordered or lost and need to be retransmitted (and thus arrive out-of-order), data from sequentially later parts of the stream may be received before sequentially earlier parts of the stream; however, the later data cannot typically be used until the earlier data has been received, incurring network latency. If multiple independent higher-level messages are encapsulated and multiplexed onto a single TCP connection, then head-of-line blocking can cause processing of a fully-received message that was sent later to wait for delivery of a message that was sent earlier.[70]
Acceleration[edit]
The idea of a TCP accelerator is to terminate TCP connections inside the network processor and then relay the data to a second connection toward the end system. The data packets that originate from the sender are buffered at the accelerator node, which is responsible for performing local retransmissions in the event of packet loss. Thus, in case of losses, the feedback loop between the sender and the receiver is shortened to the one between the acceleration node and the receiver which guarantees a faster delivery of data to the receiver.
Since TCP is a rate-adaptive protocol, the rate at which the TCP sender injects
packets into the network is directly proportional to the prevailing load condition within the network as well as the processing capacity of the receiver. The prevalent conditions within the network are judged by the sender on the basis of the acknowledgments received by it. The acceleration node splits the feedback loop between the sender and the receiver and thus guarantees a shorter round trip time (RTT) per packet. A shorter RTT is beneficial as it ensures a quicker response time to any changes in the network and a faster adaptation by the sender to combat these changes.
Disadvantages of the method include the fact that the TCP session has to be directed through the accelerator; this means that if routing changes, so that the accelerator is no longer in the path, the connection will be broken. It also destroys the end-to-end property of the TCP ack mechanism; when the ACK is received by the sender, the packet has been stored by the accelerator, not delivered to the receiver.
Debugging[edit]
A packet sniffer, which intercepts TCP traffic on a network link, can be useful in debugging networks, network stacks, and applications that use TCP by showing the user what packets are passing through a link. Some networking stacks support the SO_DEBUG socket option, which can be enabled on the socket using setsockopt. That option dumps all the packets, TCP states, and events on that socket, which is helpful in debugging. Netstat is another utility that can be used for debugging.
Alternatives[edit]
For many applications TCP is not appropriate. One problem (at least with normal implementations) is that the application cannot access the packets coming after a lost packet until the retransmitted copy of the lost packet is received. This causes problems for real-time applications such as streaming media, real-time multiplayer games and voice over IP (VoIP) where it is generally more useful to get most of the data in a timely fashion than it is to get all of the data in order.
For historical and performance reasons, most storage area networks (SANs) use Fibre Channel Protocol (FCP) over Fibre Channel connections.
Also, for embedded systems, network booting, and servers that serve simple requests from huge numbers of clients (e.g. DNS servers) the complexity of TCP can be a problem. Finally, some tricks such as transmitting data between two hosts that are both behind NAT (using STUN or similar systems) are far simpler without a relatively complex protocol like TCP in the way.
Generally, where TCP is unsuitable, the User Datagram Protocol (UDP) is used. This provides the application multiplexing and checksums that TCP does, but does not handle streams or retransmission, giving the application developer the ability to code them in a way suitable for the situation, or to replace them with other methods like forward error correction or interpolation.
Stream Control Transmission Protocol (SCTP) is another protocol that provides reliable stream oriented services similar to TCP. It is newer and considerably more complex than TCP, and has not yet seen widespread deployment. However, it is especially designed to be used in situations where reliability and near-real-time considerations are important.
Venturi Transport Protocol (VTP) is a patented proprietary protocol that is designed to replace TCP transparently to overcome perceived inefficiencies related to wireless data transport.
TCP also has issues in high-bandwidth environments. The TCP congestion avoidance algorithm works very well for ad-hoc environments where the data sender is not known in advance. If the environment is predictable, a timing based protocol such as Asynchronous Transfer Mode (ATM) can avoid TCP’s retransmits overhead.
UDP-based Data Transfer Protocol (UDT) has better efficiency and fairness than TCP in networks that have high bandwidth-delay product.[71]
Multipurpose Transaction Protocol (MTP/IP) is patented proprietary software that is designed to adaptively achieve high throughput and transaction performance in a wide variety of network conditions, particularly those where TCP is perceived to be inefficient.
Checksum computation[edit]
TCP checksum for IPv4[edit]
When TCP runs over IPv4, the method used to compute the checksum is defined as follows:[9]
The checksum field is the 16-bit ones’ complement of the ones’ complement sum of all 16-bit words in the header and text. The checksum computation needs to ensure the 16-bit alignment of the data being summed. If a segment contains an odd number of header and text octets, alignment can be achieved by padding the last octet with zeros on its right to form a 16-bit word for checksum purposes. The pad is not transmitted as part of the segment. While computing the checksum, the checksum field itself is replaced with zeros.
In other words, after appropriate padding, all 16-bit words are added using one’s complement arithmetic. The sum is then bitwise complemented and inserted as the checksum field. A pseudo-header that mimics the IPv4 packet header used in the checksum computation is shown in the table below.
| Bit offset | 0–3 | 4–7 | 8–15 | 16–31 |
|---|---|---|---|---|
| 0 | Source address | |||
| 32 | Destination address | |||
| 64 | Zeros | Protocol | TCP length | |
| 96 | Source port | Destination port | ||
| 128 | Sequence number | |||
| 160 | Acknowledgement number | |||
| 192 | Data offset | Reserved | Flags | Window |
| 224 | Checksum | Urgent pointer | ||
| 256 | Options (optional) | |||
| 256/288+ | Data |
The source and destination addresses are those of the IPv4 header. The protocol value is 6 for TCP (cf. List of IP protocol numbers). The TCP length field is the length of the TCP header and data (measured in octets).
TCP checksum for IPv6[edit]
When TCP runs over IPv6, the method used to compute the checksum is changed:[72]
Any transport or other upper-layer protocol that includes the addresses from the IP header in its checksum computation must be modified for use over IPv6, to include the 128-bit IPv6 addresses instead of 32-bit IPv4 addresses.
A pseudo-header that mimics the IPv6 header for computation of the checksum is shown below.
| Bit offset | 0–7 | 8–15 | 16–23 | 24–31 |
|---|---|---|---|---|
| 0 | Source address | |||
| 32 | ||||
| 64 | ||||
| 96 | ||||
| 128 | Destination address | |||
| 160 | ||||
| 192 | ||||
| 224 | ||||
| 256 | TCP length | |||
| 288 | Zeros | Next header = Protocol | ||
| 320 | Source port | Destination port | ||
| 352 | Sequence number | |||
| 384 | Acknowledgement number | |||
| 416 | Data offset | Reserved | Flags | Window |
| 448 | Checksum | Urgent pointer | ||
| 480 | Options (optional) | |||
| 480/512+ | Data |
- Source address: the one in the IPv6 header
- Destination address: the final destination; if the IPv6 packet doesn’t contain a Routing header, TCP uses the destination address in the IPv6 header, otherwise, at the originating node, it uses the address in the last element of the Routing header, and, at the receiving node, it uses the destination address in the IPv6 header.
- TCP length: the length of the TCP header and data
- Next Header: the protocol value for TCP
Checksum offload [edit]
Many TCP/IP software stack implementations provide options to use hardware assistance to automatically compute the checksum in the network adapter prior to transmission onto the network or upon reception from the network for validation. This may relieve the OS from using precious CPU cycles calculating the checksum. Hence, overall network performance is increased.
This feature may cause packet analyzers that are unaware or uncertain about the use of checksum offload to report invalid checksums in outbound packets that have not yet reached the network adapter.[73] This will only occur for packets that are intercepted before being transmitted by the network adapter; all packets transmitted by the network adaptor on the wire will have valid checksums.[74] This issue can also occur when monitoring packets being transmitted between virtual machines on the same host, where a virtual device driver may omit the checksum calculation (as an optimization), knowing that the checksum will be calculated later by the VM host kernel or its physical hardware.
RFC documents[edit]
- RFC 675 – Specification of Internet Transmission Control Program, December 1974 Version
- RFC 793 – TCP v4
- RFC 1122 – includes some error corrections for TCP
- RFC 1323 – TCP Extensions for High Performance [Obsoleted by RFC 7323]
- RFC 1379 – Extending TCP for Transactions—Concepts [Obsoleted by RFC 6247]
- RFC 1948 – Defending Against Sequence Number Attacks
- RFC 2018 – TCP Selective Acknowledgment Options
- RFC 5681 – TCP Congestion Control
- RFC 6247 – Moving the Undeployed TCP Extensions RFC 1072, 1106, 1110, 1145, 1146, 1379, 1644 and 1693 to Historic Status
- RFC 6298 – Computing TCP’s Retransmission Timer
- RFC 6824 – TCP Extensions for Multipath Operation with Multiple Addresses
- RFC 7323 – TCP Extensions for High Performance
- RFC 7414 – A Roadmap for TCP Specification Documents
- RFC 9293 – Transmission Control Protocol (TCP)
See also[edit]
- Connection-oriented communication
- List of TCP and UDP port numbers (a long list of ports and services)
- Micro-bursting (networking)
- T/TCP variant of TCP
- TCP global synchronization
- TCP pacing
- Transport layer § Comparison of transport layer protocols
- WTCP a proxy-based modification of TCP for wireless networks
Notes[edit]
- ^ Experimental: see RFC 3540
- ^ a b Added to header by RFC 3168
- ^ Windows size units are, by default, bytes.
- ^ Window size is relative to the segment identified by the sequence number in the acknowledgment field.
References[edit]
- ^ Vinton G. Cerf; Robert E. Kahn (May 1974). «A Protocol for Packet Network Intercommunication» (PDF). IEEE Transactions on Communications. 22 (5): 637–648. doi:10.1109/tcom.1974.1092259. Archived from the original (PDF) on March 4, 2016.
- ^ Bennett, Richard (September 2009). «Designed for Change: End-to-End Arguments, Internet Innovation, and the Net Neutrality Debate» (PDF). Information Technology and Innovation Foundation. p. 11. Retrieved 11 September 2017.
- ^ V. Cerf; Y. Dalal; C. Sunshine (December 1974). SPECIFICATION OF INTERNET TRANSMISSION CONTROL PROGRAM. Network Working Group. doi:10.17487/RFC0698. RFC 698. Obsolete. Obsoleted by RFC 7805. NIC 2. INWG 72.
- ^ «Robert E Kahn — A.M. Turing Award Laureate». amturing.acm.org.
- ^ «Vinton Cerf — A.M. Turing Award Laureate». amturing.acm.org.
- ^ a b c d e f g h i Comer, Douglas E. (2006). Internetworking with TCP/IP: Principles, Protocols, and Architecture. Vol. 1 (5th ed.). Prentice Hall. ISBN 978-0-13-187671-2.
- ^ «TCP (Transmission Control Protocol)». Retrieved 2019-06-26.
- ^ J. Postel, ed. (September 1981). INTERNET PROTOCOL — DARPA INTERNET PROGRAM PROTOCOL SPECIFICATION. IETF. doi:10.17487/RFC0791. STD 5. RFC 791. IEN 128, 123, 111, 80, 54, 44, 41, 28, 26. Internet Standard. Obsoletes RFC 760. Updated by RFC 1349, 2474 and 6864.
- ^ a b c d W. Eddy, ed. (August 2022). Transmission Control Protocol (TCP). Internet Engineering Task Force. doi:10.17487/RFC9293. ISSN 2070-1721. STD 7. RFC 9293. Internet Standard. Obsoletes RFC 793, 879, 2873, 6093, 6429, 6528 and 6691. Updates RFC 1011, 1122 and 5961.
- ^ TCP Extensions for High Performance. sec. 2.2. RFC 1323.
- ^ a b S. Floyd; J. Mahdavi; M. Mathis; A. Romanow (October 1996). TCP Selective Acknowledgment Options. IETF TCP Large Windows workgroup. doi:10.17487/RFC2018. RFC 2018. Proposed Standard. Obsoletes RFC 1072.
- ^ «RFC 1323, TCP Extensions for High Performance, Section 3.2».
- ^ «Transmission Control Protocol (TCP) Parameters: TCP Option Kind Numbers». IANA.
- ^ W. Eddy, ed. (August 2022). Transmission Control Protocol (TCP). Internet Engineering Task Force. doi:10.17487/RFC9293. ISSN 2070-1721. STD 7. RFC 9293. Internet Standard. sec. 3.3.2.
- ^ Kurose, James F. (2017). Computer networking : a top-down approach. Keith W. Ross (7th ed.). Harlow, England. p. 286. ISBN 978-0-13-359414-0. OCLC 936004518.
- ^ Tanenbaum, Andrew S. (2003-03-17). Computer Networks (Fourth ed.). Prentice Hall. ISBN 978-0-13-066102-9.
- ^ R. Braden, ed. (October 1989). Requirements for Internet Hosts — Communication Layers. Network Working Group. doi:10.17487/RFC1122. STD 3. RFC 1122. Internet Standard. sec. 4.2.2.13.
- ^ «TCP Definition». Retrieved 2011-03-12.
- ^ Mathis; Mathew; Semke; Mahdavi; Ott (1997). «The macroscopic behavior of the TCP congestion avoidance algorithm». ACM SIGCOMM Computer Communication Review. 27 (3): 67–82. CiteSeerX 10.1.1.40.7002. doi:10.1145/263932.264023. S2CID 1894993.
- ^ a b V. Paxson; M. Allman; J. Chu; M. Sargent (June 2011). Computing TCP’s Retransmission Timer. Internet Engineering Task Force. doi:10.17487/RFC6298. ISSN 2070-1721. RFC 6298. Proposed Standard. Obsoletes RFC 2988. Updates RFC 1122.
- ^ Stone; Partridge (2000). «When The CRC and TCP Checksum Disagree». ACM SIGCOMM Computer Communication Review: 309–319. CiteSeerX 10.1.1.27.7611. doi:10.1145/347059.347561. ISBN 978-1581132236. S2CID 9547018.
- ^ M. Allman; V. Paxson; E. Blanton (September 2009). TCP Congestion Control. IETF. doi:10.17487/RFC5681. RFC 5681. Draft Standard. Obsoletes RFC 2581.
- ^ D. Borman; B. Braden; V. Jacobson (September 2014). R. Scheffenegger (ed.). TCP Extensions for High Performance. Internet Engineering Task Force. doi:10.17487/RFC7323. ISSN 2070-1721. RFC 7323. Proposed Standard. Obsoletes RFC 1323.
- ^ R. Braden, ed. (October 1989). Requirements for Internet Hosts — Communication Layers. Network Working Group. doi:10.17487/RFC1122. STD 3. RFC 1122. Internet Standard. Updated by RFC 1349, 4379, 5884, 6093, 6298, 6633, 6864, 8029 and 9293.
- ^ «TCP window scaling and broken routers». LWN.net.
- ^ RFC 3522
- ^ «IP sysctl». Linux Kernel Documentation. Retrieved 15 December 2018.
- ^ Wang, Eve. «TCP timestamp is disabled». Technet — Windows Server 2012 Essentials. Microsoft. Archived from the original on 2018-12-15. Retrieved 2018-12-15.
- ^ David Murray; Terry Koziniec; Sebastian Zander; Michael Dixon; Polychronis Koutsakis (2017). «An Analysis of Changing Enterprise Network Traffic Characteristics» (PDF). The 23rd Asia-Pacific Conference on Communications (APCC 2017). Retrieved 3 October 2017.
- ^ Gont, Fernando (November 2008). «On the implementation of TCP urgent data». 73rd IETF meeting. Retrieved 2009-01-04.
- ^ Peterson, Larry (2003). Computer Networks. Morgan Kaufmann. p. 401. ISBN 978-1-55860-832-0.
- ^ Richard W. Stevens (November 2011). TCP/IP Illustrated. Vol. 1, The protocols. Addison-Wesley. pp. Chapter 20. ISBN 978-0-201-63346-7.
- ^ «Security Assessment of the Transmission Control Protocol (TCP)» (PDF). Archived from the original on March 6, 2009. Retrieved 2010-12-23.
{{cite web}}: CS1 maint: bot: original URL status unknown (link) - ^ Security Assessment of the Transmission Control Protocol (TCP)
- ^ Jakob Lell. «Quick Blind TCP Connection Spoofing with SYN Cookies». Retrieved 2014-02-05.
- ^ «Some insights about the recent TCP DoS (Denial of Service) vulnerabilities» (PDF).
- ^ «Exploiting TCP and the Persist Timer Infiniteness».
- ^ «PUSH and ACK Flood». f5.com.
- ^ «Laurent Joncheray, Simple Active Attack Against TCP, 1995″.
- ^ John T. Hagen; Barry E. Mullins (2013). TCP veto: A novel network attack and its application to SCADA protocols. Innovative Smart Grid Technologies (ISGT), 2013 IEEE PES. pp. 1–6. doi:10.1109/ISGT.2013.6497785. ISBN 978-1-4673-4896-6. S2CID 25353177.
- ^ «TCP Interactive». www.medianet.kent.edu.
- ^ J. Iyengar; C. Raiciu; S. Barre; M. Handley; A. Ford (March 2011). Architectural Guidelines for Multipath TCP Development. Internet Engineering Task Force (IETF). doi:10.17487/RFC6182. RFC 6182. Informational.
- ^ Alan Ford; C. Raiciu; M. Handley; O. Bonaventure (January 2013). TCP Extensions for Multipath Operation with Multiple Addresses. Internet Engineering Task Force. doi:10.17487/RFC6824. ISSN 2070-1721. RFC 6824. Experimental. Obsoleted by RFC 8624.
- ^ Raiciu; Barre; Pluntke; Greenhalgh; Wischik; Handley (2011). «Improving datacenter performance and robustness with multipath TCP». ACM SIGCOMM Computer Communication Review. 41 (4): 266. CiteSeerX 10.1.1.306.3863. doi:10.1145/2043164.2018467. Archived from the original on 2020-04-04. Retrieved 2011-06-29.
- ^ «MultiPath TCP — Linux Kernel implementation».
- ^ Raiciu; Paasch; Barre; Ford; Honda; Duchene; Bonaventure; Handley (2012). «How Hard Can It Be? Designing and Implementing a Deployable Multipath TCP». Usenix NSDI: 399–412.
- ^ Bonaventure; Seo (2016). «Multipath TCP Deployments». IETF Journal.
- ^ Michael Kerrisk (2012-08-01). «TCP Fast Open: expediting web services». LWN.net.
- ^ Yuchung Cheng; Jerry Chu; Sivasankar Radhakrishnan & Arvind Jain (December 2014). «TCP Fast Open». IETF. Retrieved 10 January 2015.
- ^ Mathis, Matt; Dukkipati, Nandita; Cheng, Yuchung (May 2013). «RFC 6937 — Proportional Rate Reduction for TCP». Retrieved 6 June 2014.
- ^ Grigorik, Ilya (2013). High-performance browser networking (1. ed.). Beijing: O’Reilly. ISBN 978-1449344764.
- ^ W. Simpson (January 2011). TCP Cookie Transactions (TCPCT). IETF. doi:10.17487/RFC6013. ISSN 2070-1721. RFC 6013. Obsolete. Obsoleted by RFC 7805.
- ^ A. Zimmermann; W. Eddy; L. Eggert (April 2016). Moving Outdated TCP Extensions and TCP-Related Documents to Historic or Informational Status. IETF. doi:10.17487/RFC7805. ISSN 2070-1721. RFC 7805. Informational. Obsoletes RFC 675, 721, 761, 813, 816, 879, 896 and 6013. Updates RFC 7414, 4291, 4338, 4391, 5072 and 5121.
- ^ a b «TCP performance over CDMA2000 RLP». Archived from the original on 2011-05-03. Retrieved 2010-08-30.
- ^ Muhammad Adeel & Ahmad Ali Iqbal (2004). TCP Congestion Window Optimization for CDMA2000 Packet Data Networks. International Conference on Information Technology (ITNG’07). pp. 31–35. doi:10.1109/ITNG.2007.190. ISBN 978-0-7695-2776-5. S2CID 8717768.
- ^ Trammell & Kuehlewind 2019, p. 6.
- ^ Hardie 2019, p. 3.
- ^ Fairhurst & Perkins 2021, 3. Research, Development, and Deployment.
- ^ Hardie 2019, p. 8.
- ^ Thomson & Pauly 2021, 2.3. Multi-party Interactions and Middleboxes.
- ^ Thomson & Pauly 2021, A.5. TCP.
- ^ Papastergiou et al. 2017, p. 620.
- ^ Edeline & Donnet 2019, p. 175-176.
- ^ Raiciu et al. 2012, p. 1.
- ^ Hesmans et al. 2013, p. 1.
- ^ Rybczyńska 2020.
- ^ Papastergiou et al. 2017, p. 621.
- ^ Corbet 2015.
- ^ Briscoe et al. 2006, p. 29-30.
- ^
Yunhong Gu, Xinwei Hong, and Robert L. Grossman.
«An Analysis of AIMD Algorithm with Decreasing Increases».
2004. - ^ S. Deering; R. Hinden (July 2017). Internet Protocol, Version 6 (IPv6) Specification. IETF. doi:10.17487/RFC8200. STD 86. RFC 8200. Internet Standard. Obsoletes RFC 2460.
- ^ «Wireshark: Offloading».
Wireshark captures packets before they are sent to the network adapter. It won’t see the correct checksum because it has not been calculated yet. Even worse, most OSes don’t bother initialize this data so you’re probably seeing little chunks of memory that you shouldn’t. New installations of Wireshark 1.2 and above disable IP, TCP, and UDP checksum validation by default. You can disable checksum validation in each of those dissectors by hand if needed.
- ^ «Wireshark: Checksums».
Checksum offloading often causes confusion as the network packets to be transmitted are handed over to Wireshark before the checksums are actually calculated. Wireshark gets these «empty» checksums and displays them as invalid, even though the packets will contain valid checksums when they leave the network hardware later.
Bibliography[edit]
- Trammell, Brian; Kuehlewind, Mirja (April 2019). The Wire Image of a Network Protocol. doi:10.17487/RFC8546. RFC 8546.
- Hardie, Ted, ed. (April 2019). Transport Protocol Path Signals. doi:10.17487/RFC8558. RFC 8558.
- Fairhurst, Gorry; Perkins, Colin (July 2021). Considerations around Transport Header Confidentiality, Network Operations, and the Evolution of Internet Transport Protocols. doi:10.17487/RFC9065. RFC 9065.
- Thomson, Martin; Pauly, Tommy (December 2021). Long-Term Viability of Protocol Extension Mechanisms. doi:10.17487/RFC9170. RFC 9170.
- Hesmans, Benjamin; Duchene, Fabien; Paasch, Christoph; Detal, Gregory; Bonaventure, Olivier (2013). Are TCP extensions middlebox-proof?. HotMiddlebox ’13. doi:10.1145/2535828.2535830.
- Corbet, Jonathan (8 December 2015). «Checksum offloads and protocol ossification». LWN.net.
- Briscoe, Bob; Brunstrom, Anna; Petlund, Andreas; Hayes, David; Ros, David; Tsang, Ing-Jyh; Gjessing, Stein; Fairhurst, Gorry; Griwodz, Carsten; Welzl, Michael (2016). «Reducing Internet Latency: A Survey of Techniques and Their Merits». IEEE Communications Surveys & Tutorials. 18 (3): 2149–2196. doi:10.1109/COMST.2014.2375213. hdl:2164/8018. S2CID 206576469.
- Papastergiou, Giorgos; Fairhurst, Gorry; Ros, David; Brunstrom, Anna; Grinnemo, Karl-Johan; Hurtig, Per; Khademi, Naeem; Tüxen, Michael; Welzl, Michael; Damjanovic, Dragana; Mangiante, Simone (2017). «De-Ossifying the Internet Transport Layer: A Survey and Future Perspectives». IEEE Communications Surveys & Tutorials. doi:10.1109/COMST.2016.2626780.
- Edeline, Korian; Donnet, Benoit (2019). A Bottom-Up Investigation of the Transport-Layer Ossification. 2019 Network Traffic Measurement and Analysis Conference (TMA). doi:10.23919/TMA.2019.8784690.
- Rybczyńska, Marta (13 March 2020). «A QUIC look at HTTP/3». LWN.net.
Further reading[edit]
- Stevens, W. Richard (1994-01-10). TCP/IP Illustrated, Volume 1: The Protocols. Addison-Wesley Pub. Co. ISBN 978-0-201-63346-7.
- Stevens, W. Richard; Wright, Gary R (1994). TCP/IP Illustrated, Volume 2: The Implementation. ISBN 978-0-201-63354-2.
- Stevens, W. Richard (1996). TCP/IP Illustrated, Volume 3: TCP for Transactions, HTTP, NNTP, and the UNIX Domain Protocols. ISBN 978-0-201-63495-2.**
External links[edit]
- Oral history interview with Robert E. Kahn
- IANA Port Assignments
- IANA TCP Parameters
- John Kristoff’s Overview of TCP (Fundamental concepts behind TCP and how it is used to transport data between two endpoints)
- Checksum example
- TCP tutorial
| Communication protocol | |
| Developer(s) | Vint Cerf and Bob Kahn |
|---|---|
| Introduction | 1974 |
| Based on | Transmission Control Program |
| OSI layer | 4 |
| RFC(s) | RFC 9293 |
The Transmission Control Protocol (TCP) is one of the main protocols of the Internet protocol suite. It originated in the initial network implementation in which it complemented the Internet Protocol (IP). Therefore, the entire suite is commonly referred to as TCP/IP. TCP provides reliable, ordered, and error-checked delivery of a stream of octets (bytes) between applications running on hosts communicating via an IP network. Major internet applications such as the World Wide Web, email, remote administration, and file transfer rely on TCP, which is part of the Transport Layer of the TCP/IP suite. SSL/TLS often runs on top of TCP.
TCP is connection-oriented, and a connection between client and server is established before data can be sent. The server must be listening (passive open) for connection requests from clients before a connection is established. Three-way handshake (active open), retransmission, and error detection adds to reliability but lengthens latency. Applications that do not require reliable data stream service may use the User Datagram Protocol (UDP) instead, which provides a connectionless datagram service that prioritizes time over reliability. TCP employs network congestion avoidance. However, there are vulnerabilities in TCP, including denial of service, connection hijacking, TCP veto, and reset attack.
Historical origin[edit]
In May 1974, Vint Cerf and Bob Kahn described an internetworking protocol for sharing resources using packet switching among network nodes.[1] The authors had been working with Gérard Le Lann to incorporate concepts from the French CYCLADES project into the new network.[2] The specification of the resulting protocol, RFC 675 (Specification of Internet Transmission Control Program), was written by Vint Cerf, Yogen Dalal, and Carl Sunshine, and published in December 1974. It contains the first attested use of the term internet, as a shorthand for internetwork.[3]
A central control component of this model was the Transmission Control Program that incorporated both connection-oriented links and datagram services between hosts. The monolithic Transmission Control Program was later divided into a modular architecture consisting of the Transmission Control Protocol and the Internet Protocol. This resulted in a networking model that became known informally as TCP/IP, although formally it was variously referred to as the Department of Defense (DOD) model, and ARPANET model, and eventually also as the Internet Protocol Suite.
In 2004, Vint Cerf and Bob Kahn received the Turing Award for their foundational work on TCP/IP.[4][5]
Network function[edit]
The Transmission Control Protocol provides a communication service at an intermediate level between an application program and the Internet Protocol. It provides host-to-host connectivity at the transport layer of the Internet model. An application does not need to know the particular mechanisms for sending data via a link to another host, such as the required IP fragmentation to accommodate the maximum transmission unit of the transmission medium. At the transport layer, TCP handles all handshaking and transmission details and presents an abstraction of the network connection to the application typically through a network socket interface.
At the lower levels of the protocol stack, due to network congestion, traffic load balancing, or unpredictable network behaviour, IP packets may be lost, duplicated, or delivered out of order. TCP detects these problems, requests re-transmission of lost data, rearranges out-of-order data and even helps minimize network congestion to reduce the occurrence of the other problems. If the data still remains undelivered, the source is notified of this failure. Once the TCP receiver has reassembled the sequence of octets originally transmitted, it passes them to the receiving application. Thus, TCP abstracts the application’s communication from the underlying networking details.
TCP is used extensively by many internet applications, including the World Wide Web (WWW), email, File Transfer Protocol, Secure Shell, peer-to-peer file sharing, and streaming media.
TCP is optimized for accurate delivery rather than timely delivery and can incur relatively long delays (on the order of seconds) while waiting for out-of-order messages or re-transmissions of lost messages. Therefore, it is not particularly suitable for real-time applications such as voice over IP. For such applications, protocols like the Real-time Transport Protocol (RTP) operating over the User Datagram Protocol (UDP) are usually recommended instead.[6]
TCP is a reliable byte stream delivery service which guarantees that all bytes received will be identical and in the same order as those sent. Since packet transfer by many networks is not reliable, TCP achieves this using a technique known as positive acknowledgement with re-transmission. This requires the receiver to respond with an acknowledgement message as it receives the data. The sender keeps a record of each packet it sends and maintains a timer from when the packet was sent. The sender re-transmits a packet if the timer expires before receiving the acknowledgement. The timer is needed in case a packet gets lost or corrupted.[6]
While IP handles actual delivery of the data, TCP keeps track of segments — the individual units of data transmission that a message is divided into for efficient routing through the network. For example, when an HTML file is sent from a web server, the TCP software layer of that server divides the file into segments and forwards them individually to the internet layer in the network stack. The internet layer software encapsulates each TCP segment into an IP packet by adding a header that includes (among other data) the destination IP address. When the client program on the destination computer receives them, the TCP software in the transport layer re-assembles the segments and ensures they are correctly ordered and error-free as it streams the file contents to the receiving application.
TCP segment structure[edit]
Transmission Control Protocol accepts data from a data stream, divides it into chunks, and adds a TCP header creating a TCP segment. The TCP segment is then encapsulated into an Internet Protocol (IP) datagram, and exchanged with peers.[7]
The term TCP packet appears in both informal and formal usage, whereas in more precise terminology segment refers to the TCP protocol data unit (PDU), datagram[8]: 5–6 to the IP PDU, and frame to the data link layer PDU:
Processes transmit data by calling on the TCP and passing buffers of data as arguments. The TCP packages the data from these buffers into segments and calls on the internet module [e.g. IP] to transmit each segment to the destination TCP.[9]
A TCP segment consists of a segment header and a data section. The segment header contains 10 mandatory fields, and an optional extension field (Options, pink background in table). The data section follows the header and is the payload data carried for the application. The length of the data section is not specified in the segment header; it can be calculated by subtracting the combined length of the segment header and IP header from the total IP datagram length specified in the IP header.
| Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octet | Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 0 | Source port | Destination port | ||||||||||||||||||||||||||||||
| 4 | 32 | Sequence number | |||||||||||||||||||||||||||||||
| 8 | 64 | Acknowledgment number (if ACK set) | |||||||||||||||||||||||||||||||
| 12 | 96 | Data offset | Reserved 0 0 0 | NS | CWR | ECE | URG | ACK | PSH | RST | SYN | FIN | Window Size | ||||||||||||||||||||
| 16 | 128 | Checksum | Urgent pointer (if URG set) | ||||||||||||||||||||||||||||||
| 20 | 160 | Options (if data offset > 5. Padded at the end with «0» bits if necessary.) | |||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
| 60 | 480 |
- Source port (16 bits)
- Identifies the sending port.
- Destination port (16 bits)
- Identifies the receiving port.
- Sequence number (32 bits)
- Has a dual role:
- If the SYN flag is set (1), then this is the initial sequence number. The sequence number of the actual first data byte and the acknowledged number in the corresponding ACK are then this sequence number plus 1.
- If the SYN flag is clear (0), then this is the accumulated sequence number of the first data byte of this segment for the current session.
- Acknowledgment number (32 bits)
- If the ACK flag is set then the value of this field is the next sequence number that the sender of the ACK is expecting. This acknowledges receipt of all prior bytes (if any). The first ACK sent by each end acknowledges the other end’s initial sequence number itself, but no data.
- Data offset (4 bits)
- Specifies the size of the TCP header in 32-bit words. The minimum size header is 5 words and the maximum is 15 words thus giving the minimum size of 20 bytes and maximum of 60 bytes, allowing for up to 40 bytes of options in the header. This field gets its name from the fact that it is also the offset from the start of the TCP segment to the actual data.
- Reserved (3 bits)
- For future use and should be set to zero.
- Flags (9 bits)
- Contains 9 1-bit flags (control bits) as follows:
- NS (1 bit): ECN-nonce — concealment protection[a]
- CWR (1 bit): Congestion window reduced (CWR) flag is set by the sending host to indicate that it received a TCP segment with the ECE flag set and had responded in congestion control mechanism.[b]
- ECE (1 bit): ECN-Echo has a dual role, depending on the value of the SYN flag. It indicates:
-
- If the SYN flag is set (1), that the TCP peer is ECN capable.
- If the SYN flag is clear (0), that a packet with Congestion Experienced flag set (ECN=11) in the IP header was received during normal transmission.[b] This serves as an indication of network congestion (or impending congestion) to the TCP sender.
- URG (1 bit): Indicates that the Urgent pointer field is significant
- ACK (1 bit): Indicates that the Acknowledgment field is significant. All packets after the initial SYN packet sent by the client should have this flag set.
- PSH (1 bit): Push function. Asks to push the buffered data to the receiving application.
- RST (1 bit): Reset the connection
- SYN (1 bit): Synchronize sequence numbers. Only the first packet sent from each end should have this flag set. Some other flags and fields change meaning based on this flag, and some are only valid when it is set, and others when it is clear.
- FIN (1 bit): Last packet from sender
- Window size (16 bits)
- The size of the receive window, which specifies the number of window size units[c] that the sender of this segment is currently willing to receive.[d] (See § Flow control and § Window scaling.)
- Checksum (16 bits)
- The 16-bit checksum field is used for error-checking of the TCP header, the payload and an IP pseudo-header. The pseudo-header consists of the source IP address, the destination IP address, the protocol number for the TCP protocol (6) and the length of the TCP headers and payload (in bytes).
- Urgent pointer (16 bits)
- If the URG flag is set, then this 16-bit field is an offset from the sequence number indicating the last urgent data byte.
- Options (Variable 0–320 bits, in units of 32 bits)
- The length of this field is determined by the data offset field. Options have up to three fields: Option-Kind (1 byte), Option-Length (1 byte), Option-Data (variable). The Option-Kind field indicates the type of option and is the only field that is not optional. Depending on Option-Kind value, the next two fields may be set. Option-Length indicates the total length of the option, and Option-Data contains data associated with the option, if applicable. For example, an Option-Kind byte of 1 indicates that this is a no operation option used only for padding, and does not have an Option-Length or Option-Data fields following it. An Option-Kind byte of 0 marks the end of options, and is also only one byte. An Option-Kind byte of 2 is used to indicate Maximum Segment Size option, and will be followed by an Option-Length byte specifying the length of the MSS field. Option-Length is the total length of the given options field, including Option-Kind and Option-Length fields. So while the MSS value is typically expressed in two bytes, Option-Length will be 4. As an example, an MSS option field with a value of 0x05B4 is coded as (0x02 0x04 0x05B4) in the TCP options section.
- Some options may only be sent when SYN is set; they are indicated below as
[SYN]. Option-Kind and standard lengths given as (Option-Kind, Option-Length).
-
Option-Kind Option-Length Option-Data Purpose Notes 0 — — End of options list 1 — — No operation This may be used to align option fields on 32-bit boundaries for better performance. 2 4 SS Maximum segment size See § Maximum segment size [SYN]3 3 S Window scale See § Window scaling for details[10] [SYN]4 2 — Selective Acknowledgement permitted See § Selective acknowledgments for details[11]: §2 [SYN]5 N (10, 18, 26, or 34) BBBB, EEEE, … Selective ACKnowledgement (SACK)[11]: §3 These first two bytes are followed by a list of 1–4 blocks being selectively acknowledged, specified as 32-bit begin/end pointers. 8 10 TTTT, EEEE Timestamp and echo of previous timestamp See § TCP timestamps for details[12]
- The remaining Option-Kind values are historical, obsolete, experimental, not yet standardized, or unassigned. Option number assignments are maintained by the IANA.[13]
- Padding
- The TCP header padding is used to ensure that the TCP header ends, and data begins, on a 32-bit boundary. The padding is composed of zeros.[9]
Protocol operation[edit]
A Simplified TCP State Diagram. See TCP EFSM diagram for more detailed diagrams, including detail on the ESTABLISHED state.
TCP protocol operations may be divided into three phases. Connection establishment is a multi-step handshake process that establishes a connection before entering the data transfer phase. After data transfer is completed, the connection termination closes the connection and releases all allocated resources.
A TCP connection is managed by an operating system through a resource that represents the local end-point for communications, the Internet socket. During the lifetime of a TCP connection, the local end-point undergoes a series of state changes:[14]
| State | Endpoint | Description |
|---|---|---|
| LISTEN | Server | Waiting for a connection request from any remote TCP end-point. |
| SYN-SENT | Client | Waiting for a matching connection request after having sent a connection request. |
| SYN-RECEIVED | Server | Waiting for a confirming connection request acknowledgment after having both received and sent a connection request. |
| ESTABLISHED | Server and client | An open connection, data received can be delivered to the user. The normal state for the data transfer phase of the connection. |
| FIN-WAIT-1 | Server and client | Waiting for a connection termination request from the remote TCP, or an acknowledgment of the connection termination request previously sent. |
| FIN-WAIT-2 | Server and client | Waiting for a connection termination request from the remote TCP. |
| CLOSE-WAIT | Server and client | Waiting for a connection termination request from the local user. |
| CLOSING | Server and client | Waiting for a connection termination request acknowledgment from the remote TCP. |
| LAST-ACK | Server and client | Waiting for an acknowledgment of the connection termination request previously sent to the remote TCP (which includes an acknowledgment of its connection termination request). |
| TIME-WAIT | Server or client | Waiting for enough time to pass to be sure that all remaining packets on the connection have expired. |
| CLOSED | Server and client | No connection state at all. |
Connection establishment[edit]
Before a client attempts to connect with a server, the server must first bind to and listen at a port to open it up for connections: this is called a passive open. Once the passive open is established, a client may establish a connection by initiating an active open using the three-way (or 3-step) handshake:
- SYN: The active open is performed by the client sending a SYN to the server. The client sets the segment’s sequence number to a random value A.
- SYN-ACK: In response, the server replies with a SYN-ACK. The acknowledgment number is set to one more than the received sequence number i.e. A+1, and the sequence number that the server chooses for the packet is another random number, B.
- ACK: Finally, the client sends an ACK back to the server. The sequence number is set to the received acknowledgment value i.e. A+1, and the acknowledgment number is set to one more than the received sequence number i.e. B+1.
Steps 1 and 2 establish and acknowledge the sequence number for one direction. Steps 2 and 3 establish and acknowledge the sequence number for the other direction. Following the completion of these steps, both the client and server have received acknowledgments and a full-duplex communication is established.
Connection termination[edit]
The connection termination phase uses a four-way handshake, with each side of the connection terminating independently. When an endpoint wishes to stop its half of the connection, it transmits a FIN packet, which the other end acknowledges with an ACK. Therefore, a typical tear-down requires a pair of FIN and ACK segments from each TCP endpoint. After the side that sent the first FIN has responded with the final ACK, it waits for a timeout before finally closing the connection, during which time the local port is unavailable for new connections; this state lets the TCP client resend the final acknowledgement to the server in case the ACK is lost in transit. The time duration is implementation-dependent, but some common values are 30 seconds, 1 minute, and 2 minutes. After the timeout, the client enters the CLOSED state and the local port becomes available for new connections.[15]
It is also possible to terminate the connection by a 3-way handshake, when host A sends a FIN and host B replies with a FIN & ACK (combining two steps into one) and host A replies with an ACK.[16]
Some operating systems, such as Linux and HP-UX,[citation needed] implement a half-duplex close sequence. If the host actively closes a connection, while still having unread incoming data available, the host sends the signal RST (losing any received data) instead of FIN. This assures that a TCP application is aware there was a data loss.[17]
A connection can be in a half-open state, in which case one side has terminated the connection, but the other has not. The side that has terminated can no longer send any data into the connection, but the other side can. The terminating side should continue reading the data until the other side terminates as well.[citation needed]
Resource usage[edit]
Most implementations allocate an entry in a table that maps a session to a running operating system process. Because TCP packets do not include a session identifier, both endpoints identify the session using the client’s address and port. Whenever a packet is received, the TCP implementation must perform a lookup on this table to find the destination process. Each entry in the table is known as a Transmission Control Block or TCB. It contains information about the endpoints (IP and port), status of the connection, running data about the packets that are being exchanged and buffers for sending and receiving data.
The number of sessions in the server side is limited only by memory and can grow as new connections arrive, but the client must allocate an ephemeral port before sending the first SYN to the server. This port remains allocated during the whole conversation and effectively limits the number of outgoing connections from each of the client’s IP addresses. If an application fails to properly close unrequired connections, a client can run out of resources and become unable to establish new TCP connections, even from other applications.
Both endpoints must also allocate space for unacknowledged packets and received (but unread) data.
Data transfer[edit]
The Transmission Control Protocol differs in several key features compared to the User Datagram Protocol:
- Ordered data transfer: the destination host rearranges segments according to a sequence number[6]
- Retransmission of lost packets: any cumulative stream not acknowledged is retransmitted[6]
- Error-free data transfer: corrupted packets are treated as lost and are retransmitted[18]
- Flow control: limits the rate a sender transfers data to guarantee reliable delivery. The receiver continually hints the sender on how much data can be received. When the receiving host’s buffer fills, the next acknowledgment suspends the transfer and allows the data in the buffer to be processed.[6]
- Congestion control: lost packets (presumed due to congestion) trigger a reduction in data delivery rate[6]
Reliable transmission[edit]
TCP uses a sequence number to identify each byte of data. The sequence number identifies the order of the bytes sent from each computer so that the data can be reconstructed in order, regardless of any out-of-order delivery that may occur. The sequence number of the first byte is chosen by the transmitter for the first packet, which is flagged SYN. This number can be arbitrary, and should, in fact, be unpredictable to defend against TCP sequence prediction attacks.
Acknowledgements (ACKs) are sent with a sequence number by the receiver of data to tell the sender that data has been received to the specified byte. ACKs do not imply that the data has been delivered to the application, they merely signify that it is now the receiver’s responsibility to deliver the data.
Reliability is achieved by the sender detecting lost data and retransmitting it. TCP uses two primary techniques to identify loss. Retransmission timeout (RTO) and duplicate cumulative acknowledgements (DupAcks).
Dupack-based retransmission[edit]
If a single segment (say segment number 100) in a stream is lost, then the receiver cannot acknowledge packets above that segment number (100) because it uses cumulative ACKs. Hence the receiver acknowledges packet 99 again on the receipt of another data packet. This duplicate acknowledgement is used as a signal for packet loss. That is, if the sender receives three duplicate acknowledgements, it retransmits the last unacknowledged packet. A threshold of three is used because the network may reorder segments causing duplicate acknowledgements. This threshold has been demonstrated to avoid spurious retransmissions due to reordering.[19] Some TCP implementation use selective acknowledgements (SACKs) to provide explicit feedback about the segments that have been received. This greatly improves TCP’s ability to retransmit the right segments.
Timeout-based retransmission[edit]
When a sender transmits a segment, it initializes a timer with a conservative estimate of the arrival time of the acknowledgement. The segment is retransmitted if the timer expires, with a new timeout threshold of twice the previous value, resulting in exponential backoff behavior. Typically, the initial timer value is
Error detection[edit]
Sequence numbers allow receivers to discard duplicate packets and properly sequence out-of-order packets. Acknowledgments allow senders to determine when to retransmit lost packets.
To assure correctness a checksum field is included; see § Checksum computation for details. The TCP checksum is a weak check by modern standards and is normally paired with a CRC integrity check at layer 2, below both TCP and IP, such as is used in PPP or the Ethernet frame. However, introduction of errors in packets between CRC-protected hops is common and the 16-bit TCP checksum catches most of these.[21]
Flow control[edit]
TCP uses an end-to-end flow control protocol to avoid having the sender send data too fast for the TCP receiver to receive and process it reliably. Having a mechanism for flow control is essential in an environment where machines of diverse network speeds communicate. For example, if a PC sends data to a smartphone that is slowly processing received data, the smartphone must be able to regulate the data flow so as not to be overwhelmed.[6]
TCP uses a sliding window flow control protocol. In each TCP segment, the receiver specifies in the receive window field the amount of additionally received data (in bytes) that it is willing to buffer for the connection. The sending host can send only up to that amount of data before it must wait for an acknowledgement and receive window update from the receiving host.
TCP sequence numbers and receive windows behave very much like a clock. The receive window shifts each time the receiver receives and acknowledges a new segment of data. Once it runs out of sequence numbers, the sequence number loops back to 0.
When a receiver advertises a window size of 0, the sender stops sending data and starts its persist timer. The persist timer is used to protect TCP from a deadlock situation that could arise if a subsequent window size update from the receiver is lost, and the sender cannot send more data until receiving a new window size update from the receiver. When the persist timer expires, the TCP sender attempts recovery by sending a small packet so that the receiver responds by sending another acknowledgement containing the new window size.
If a receiver is processing incoming data in small increments, it may repeatedly advertise a small receive window. This is referred to as the silly window syndrome, since it is inefficient to send only a few bytes of data in a TCP segment, given the relatively large overhead of the TCP header.
Congestion control[edit]
The final main aspect of TCP is congestion control. TCP uses a number of mechanisms to achieve high performance and avoid congestive collapse, a gridlock situation where network performance is severely degraded. These mechanisms control the rate of data entering the network, keeping the data flow below a rate that would trigger collapse. They also yield an approximately max-min fair allocation between flows.
Acknowledgments for data sent, or the lack of acknowledgments, are used by senders to infer network conditions between the TCP sender and receiver. Coupled with timers, TCP senders and receivers can alter the behavior of the flow of data. This is more generally referred to as congestion control or congestion avoidance.
Modern implementations of TCP contain four intertwined algorithms: slow start, congestion avoidance, fast retransmit, and fast recovery.[22]
In addition, senders employ a retransmission timeout (RTO) that is based on the estimated round-trip time (RTT) between the sender and receiver, as well as the variance in this round-trip time.[20] There are subtleties in the estimation of RTT. For example, senders must be careful when calculating RTT samples for retransmitted packets; typically they use Karn’s Algorithm or TCP timestamps.[23] These individual RTT samples are then averaged over time to create a smoothed round trip time (SRTT) using Jacobson’s algorithm. This SRTT value is what is used as the round-trip time estimate.
Enhancing TCP to reliably handle loss, minimize errors, manage congestion and go fast in very high-speed environments are ongoing areas of research and standards development. As a result, there are a number of TCP congestion avoidance algorithm variations.
Maximum segment size[edit]
The maximum segment size (MSS) is the largest amount of data, specified in bytes, that TCP is willing to receive in a single segment. For best performance, the MSS should be set small enough to avoid IP fragmentation, which can lead to packet loss and excessive retransmissions. To accomplish this, typically the MSS is announced by each side using the MSS option when the TCP connection is established. The option value is derived from the maximum transmission unit (MTU) size of the data link layer of the networks to which the sender and receiver are directly attached. TCP senders can use path MTU discovery to infer the minimum MTU along the network path between the sender and receiver, and use this to dynamically adjust the MSS to avoid IP fragmentation within the network.
MSS announcement may also be called MSS negotiation but, strictly speaking, the MSS is not negotiated. Two completely independent values of MSS are permitted for the two directions of data flow in a TCP connection,[24][9] so there is no need to agree on a common MSS configuration for a bidirectional connection.
Selective acknowledgments[edit]
Relying purely on the cumulative acknowledgment scheme employed by the original TCP can lead to inefficiencies when packets are lost. For example, suppose bytes with sequence number 1,000 to 10,999 are sent in 10 different TCP segments of equal size, and the second segment (sequence numbers 2,000 to 2,999) is lost during transmission. In a pure cumulative acknowledgment protocol, the receiver can only send a cumulative ACK value of 2,000 (the sequence number immediately following the last sequence number of the received data) and cannot say that it received bytes 3,000 to 10,999 successfully. Thus the sender may then have to resend all data starting with sequence number 2,000.
To alleviate this issue TCP employs the selective acknowledgment (SACK) option, defined in 1996 in RFC 2018, which allows the receiver to acknowledge discontinuous blocks of packets that were received correctly, in addition to the sequence number immediately following the last sequence number of the last contiguous byte received successively, as in the basic TCP acknowledgment. The acknowledgment can include a number of SACK blocks, where each SACK block is conveyed by the Left Edge of Block (the first sequence number of the block) and the Right Edge of Block (the sequence number immediately following the last sequence number of the block), with a Block being a contiguous range that the receiver correctly received. In the example above, the receiver would send an ACK segment with a cumulative ACK value of 2,000 and a SACK option header with sequence numbers 3,000 and 11,000. The sender would accordingly retransmit only the second segment with sequence numbers 2,000 to 2,999.
A TCP sender may interpret an out-of-order segment delivery as a lost segment. If it does so, the TCP sender will retransmit the segment previous to the out-of-order packet and slow its data delivery rate for that connection. The duplicate-SACK option, an extension to the SACK option that was defined in May 2000 in RFC 2883, solves this problem. The TCP receiver sends a D-ACK to indicate that no segments were lost, and the TCP sender can then reinstate the higher transmission rate.
The SACK option is not mandatory and comes into operation only if both parties support it. This is negotiated when a connection is established. SACK uses a TCP header option (see § TCP segment structure for details). The use of SACK has become widespread—all popular TCP stacks support it. Selective acknowledgment is also used in Stream Control Transmission Protocol (SCTP).
Window scaling[edit]
For more efficient use of high-bandwidth networks, a larger TCP window size may be used. A 16-bit TCP window size field controls the flow of data and its value is limited to 65,535 bytes. Since the size field cannot be expanded beyond this limit, a scaling factor is used. The TCP window scale option, as defined in RFC 1323, is an option used to increase the maximum window size to 1 gigabyte. Scaling up to these larger window sizes is necessary for TCP tuning.
The window scale option is used only during the TCP 3-way handshake. The window scale value represents the number of bits to left-shift the 16-bit window size field when interpreting it. The window scale value can be set from 0 (no shift) to 14 for each direction independently. Both sides must send the option in their SYN segments to enable window scaling in either direction.
Some routers and packet firewalls rewrite the window scaling factor during a transmission. This causes sending and receiving sides to assume different TCP window sizes. The result is non-stable traffic that may be very slow. The problem is visible on some sites behind a defective router.[25]
TCP timestamps[edit]
TCP timestamps, defined in RFC 1323 in 1992, can help TCP determine in which order packets were sent. TCP timestamps are not normally aligned to the system clock and start at some random value. Many operating systems will increment the timestamp for every elapsed millisecond; however, the RFC only states that the ticks should be proportional.
There are two timestamp fields:
- a 4-byte sender timestamp value (my timestamp)
- a 4-byte echo reply timestamp value (the most recent timestamp received from you).
TCP timestamps are used in an algorithm known as Protection Against Wrapped Sequence numbers, or PAWS. PAWS is used when the receive window crosses the sequence number wraparound boundary. In the case where a packet was potentially retransmitted, it answers the question: «Is this sequence number in the first 4 GB or the second?» And the timestamp is used to break the tie.
Also, the Eifel detection algorithm uses TCP timestamps to determine if retransmissions are occurring because packets are lost or simply out of order.[26]
TCP timestamps are enabled by default in Linux,[27] and disabled by default in Windows Server 2008, 2012 and 2016.[28]
Recent Statistics show that the level of TCP timestamp adoption has stagnated, at ~40%, owing to Windows Server dropping support since Windows Server 2008.[29]
Out-of-band data[edit]
It is possible to interrupt or abort the queued stream instead of waiting for the stream to finish. This is done by specifying the data as urgent. This marks the transmission as out-of-band data (OOB) and tells the receiving program to process it immediately. When finished, TCP informs the application and resumes the stream queue. An example is when TCP is used for a remote login session where the user can send a keyboard sequence that interrupts or aborts the remotely-running program without waiting for the program to finish its current transfer.[6]
The urgent pointer only alters the processing on the remote host and doesn’t expedite any processing on the network itself. The capability is implemented differently or poorly on different systems or may not be supported. Where it is available, it is prudent to assume only single bytes of OOB data will be reliably handled.[30][31] Since the feature is not frequently used, it is not well tested on some platforms and has been associated with vunerabilities, WinNuke for instance.
Forcing data delivery[edit]
Normally, TCP waits for 200 ms for a full packet of data to send (Nagle’s Algorithm tries to group small messages into a single packet). This wait creates small, but potentially serious delays if repeated constantly during a file transfer. For example, a typical send block would be 4 KB, a typical MSS is 1460, so 2 packets go out on a 10 Mbit/s ethernet taking ~1.2 ms each followed by a third carrying the remaining 1176 after a 197 ms pause because TCP is waiting for a full buffer.
In the case of telnet, each user keystroke is echoed back by the server before the user can see it on the screen. This delay would become very annoying.
Setting the socket option TCP_NODELAY overrides the default 200 ms send delay. Application programs use this socket option to force output to be sent after writing a character or line of characters.
The RFC defines the PSH push bit as «a message to the receiving TCP stack to send this data immediately up to the receiving application».[6] There is no way to indicate or control it in user space using Berkeley sockets and it is controlled by protocol stack only.[32]
Vulnerabilities[edit]
TCP may be attacked in a variety of ways. The results of a thorough security assessment of TCP, along with possible mitigations for the identified issues, were published in 2009,[33] and is currently[when?] being pursued within the IETF.[34]
Denial of service[edit]
By using a spoofed IP address and repeatedly sending purposely assembled SYN packets, followed by many ACK packets, attackers can cause the server to consume large amounts of resources keeping track of the bogus connections. This is known as a SYN flood attack. Proposed solutions to this problem include SYN cookies and cryptographic puzzles, though SYN cookies come with their own set of vulnerabilities.[35] Sockstress is a similar attack, that might be mitigated with system resource management.[36] An advanced DoS attack involving the exploitation of the TCP Persist Timer was analyzed in Phrack #66.[37] PUSH and ACK floods are other variants.[38]
Connection hijacking[edit]
An attacker who is able to eavesdrop a TCP session and redirect packets can hijack a TCP connection. To do so, the attacker learns the sequence number from the ongoing communication and forges a false segment that looks like the next segment in the stream. Such a simple hijack can result in one packet being erroneously accepted at one end. When the receiving host acknowledges the extra segment to the other side of the connection, synchronization is lost. Hijacking might be combined with Address Resolution Protocol (ARP) or routing attacks that allow taking control of the packet flow, so as to get permanent control of the hijacked TCP connection.[39]
Impersonating a different IP address was not difficult prior to RFC 1948, when the initial sequence number was easily guessable. That allowed an attacker to blindly send a sequence of packets that the receiver would believe to come from a different IP address, without the need to deploy ARP or routing attacks: it is enough to ensure that the legitimate host of the impersonated IP address is down, or bring it to that condition using denial-of-service attacks. This is why the initial sequence number is now chosen at random.
TCP veto[edit]
An attacker who can eavesdrop and predict the size of the next packet to be sent can cause the receiver to accept a malicious payload without disrupting the existing connection. The attacker injects a malicious packet with the sequence number and a payload size of the next expected packet. When the legitimate packet is ultimately received, it is found to have the same sequence number and length as a packet already received and is silently dropped as a normal duplicate packet—the legitimate packet is «vetoed» by the malicious packet. Unlike in connection hijacking, the connection is never desynchronized and communication continues as normal after the malicious payload is accepted. TCP veto gives the attacker less control over the communication, but makes the attack particularly resistant to detection. The large increase in network traffic from the ACK storm is avoided. The only evidence to the receiver that something is amiss is a single duplicate packet, a normal occurrence in an IP network. The sender of the vetoed packet never sees any evidence of an attack.[40]
Another vulnerability is the TCP reset attack.
TCP ports[edit]
TCP and UDP use port numbers to identify sending and receiving application end-points on a host, often called Internet sockets. Each side of a TCP connection has an associated 16-bit unsigned port number (0-65535) reserved by the sending or receiving application. Arriving TCP packets are identified as belonging to a specific TCP connection by its sockets, that is, the combination of source host address, source port, destination host address, and destination port. This means that a server computer can provide several clients with several services simultaneously, as long as a client takes care of initiating any simultaneous connections to one destination port from different source ports.
Port numbers are categorized into three basic categories: well-known, registered, and dynamic/private. The well-known ports are assigned by the Internet Assigned Numbers Authority (IANA) and are typically used by system-level or root processes. Well-known applications running as servers and passively listening for connections typically use these ports. Some examples include: FTP (20 and 21), SSH (22), TELNET (23), SMTP (25), HTTP over SSL/TLS (443), and HTTP (80). Note, as of the latest standard, HTTP/3, QUIC is used as a transport instead of TCP. Registered ports are typically used by end user applications as ephemeral source ports when contacting servers, but they can also identify named services that have been registered by a third party. Dynamic/private ports can also be used by end user applications, but are less commonly so. Dynamic/private ports do not contain any meaning outside of any particular TCP connection.
Network Address Translation (NAT), typically uses dynamic port numbers, on the («Internet-facing») public side, to disambiguate the flow of traffic that is passing between a public network and a private subnetwork, thereby allowing many IP addresses (and their ports) on the subnet to be serviced by a single public-facing address.
Development[edit]
TCP is a complex protocol. However, while significant enhancements have been made and proposed over the years, its most basic operation has not changed significantly since its first specification RFC 675 in 1974, and the v4 specification RFC 793, published in September 1981. RFC 1122, Host Requirements for Internet Hosts, clarified a number of TCP protocol implementation requirements. A list of the 8 required specifications and over 20 strongly encouraged enhancements is available in RFC 7414. Among this list is RFC 2581, TCP Congestion Control, one of the most important TCP-related RFCs in recent years, describes updated algorithms that avoid undue congestion. In 2001, RFC 3168 was written to describe Explicit Congestion Notification (ECN), a congestion avoidance signaling mechanism.
The original TCP congestion avoidance algorithm was known as «TCP Tahoe», but many alternative algorithms have since been proposed (including TCP Reno, TCP Vegas, FAST TCP, TCP New Reno, and TCP Hybla).
TCP Interactive (iTCP) [41] is a research effort into TCP extensions that allows applications to subscribe to TCP events and register handler components that can launch applications for various purposes, including application-assisted congestion control.
Multipath TCP (MPTCP) [42][43] is an ongoing effort within the IETF that aims at allowing a TCP connection to use multiple paths to maximize resource usage and increase redundancy. The redundancy offered by Multipath TCP in the context of wireless networks enables the simultaneous utilization of different networks, which brings higher throughput and better handover capabilities. Multipath TCP also brings performance benefits in datacenter environments.[44] The reference implementation[45] of Multipath TCP is being developed in the Linux kernel.[46] Multipath TCP is used to support the Siri voice recognition application on iPhones, iPads and Macs [47]
tcpcrypt is an extension proposed in July 2010 to provide transport-level encryption directly in TCP itself. It is designed to work transparently and not require any configuration. Unlike TLS (SSL), tcpcrypt itself does not provide authentication, but provides simple primitives down to the application to do that. As of 2010, the first tcpcrypt IETF draft has been published and implementations exist for several major platforms.
TCP Fast Open is an extension to speed up the opening of successive TCP connections between two endpoints. It works by skipping the three-way handshake using a cryptographic «cookie». It is similar to an earlier proposal called T/TCP, which was not widely adopted due to security issues.[48] TCP Fast Open was published as RFC 7413 in 2014.[49]
Proposed in May 2013, Proportional Rate Reduction (PRR) is a TCP extension developed by Google engineers. PRR ensures that the TCP window size after recovery is as close to the slow start threshold as possible.[50] The algorithm is designed to improve the speed of recovery and is the default congestion control algorithm in Linux 3.2+ kernels.[51]
Deprecated proposals[edit]
TCP Cookie Transactions (TCPCT) is an extension proposed in December 2009[52] to secure servers against denial-of-service attacks. Unlike SYN cookies, TCPCT does not conflict with other TCP extensions such as window scaling. TCPCT was designed due to necessities of DNSSEC, where servers have to handle large numbers of short-lived TCP connections. In 2016, TCPCT was deprecated in favor of TCP Fast Open. Status of the original RFC was changed to «historic».[53]
TCP over wireless networks[edit]
TCP was originally designed for wired networks. Packet loss is considered to be the result of network congestion and the congestion window size is reduced dramatically as a precaution. However, wireless links are known to experience sporadic and usually temporary losses due to fading, shadowing, hand off, interference, and other radio effects, that are not strictly congestion. After the (erroneous) back-off of the congestion window size, due to wireless packet loss, there may be a congestion avoidance phase with a conservative decrease in window size. This causes the radio link to be underutilized. Extensive research on combating these harmful effects has been conducted. Suggested solutions can be categorized as end-to-end solutions, which require modifications at the client or server,[54] link layer solutions, such as Radio Link Protocol (RLP) in cellular networks, or proxy-based solutions which require some changes in the network without modifying end nodes.[54][55]
A number of alternative congestion control algorithms, such as Vegas, Westwood, Veno, and Santa Cruz, have been proposed to help solve the wireless problem.[citation needed]
Hardware implementations[edit]
One way to overcome the processing power requirements of TCP is to build hardware implementations of it, widely known as TCP offload engines (TOE). The main problem of TOEs is that they are hard to integrate into computing systems, requiring extensive changes in the operating system of the computer or device. One company to develop such a device was Alacritech.
Wire image and ossification[edit]
The wire image of TCP provides significant information-gathering and modification opportunities to on-path observers, as the protocol metadata is transmitted in cleartext.[56][57] While this transparency is useful to network operators and researchers,[59] information gathered from protocol metadata may reduce the end-user’s privacy.[60] This visibility and malleability of metadata has led to TCP being difficult to extend—a case of protocol ossification—as any intermediate node (a ‘middlebox’) can make decisions based on that metadata or even modify it,[61][62] breaking the end-to-end principle.[63] One measurement found that a third of paths across the Internet encounter at least one intermediary that modifies TCP metadata, and 6.5% of paths encounter harmful ossifying effects from intermediaries.[64] Avoiding extensibility hazards from intermediaries placed significant constraints on the design of MPTCP,[65][66] and difficulties caused by intermediaries have hindered the deployment of TCP Fast Open in web browsers.[67] Another source of ossification is the difficulty of modification of TCP functions at the endpoints, typically in the operating system kernel[68] or in hardware with a TCP offload engine.[69]
Performance[edit]
As TCP provides applications with the abstraction of a reliable byte stream, it can suffer from head-of-line blocking: if packets are reordered or lost and need to be retransmitted (and thus arrive out-of-order), data from sequentially later parts of the stream may be received before sequentially earlier parts of the stream; however, the later data cannot typically be used until the earlier data has been received, incurring network latency. If multiple independent higher-level messages are encapsulated and multiplexed onto a single TCP connection, then head-of-line blocking can cause processing of a fully-received message that was sent later to wait for delivery of a message that was sent earlier.[70]
Acceleration[edit]
The idea of a TCP accelerator is to terminate TCP connections inside the network processor and then relay the data to a second connection toward the end system. The data packets that originate from the sender are buffered at the accelerator node, which is responsible for performing local retransmissions in the event of packet loss. Thus, in case of losses, the feedback loop between the sender and the receiver is shortened to the one between the acceleration node and the receiver which guarantees a faster delivery of data to the receiver.
Since TCP is a rate-adaptive protocol, the rate at which the TCP sender injects
packets into the network is directly proportional to the prevailing load condition within the network as well as the processing capacity of the receiver. The prevalent conditions within the network are judged by the sender on the basis of the acknowledgments received by it. The acceleration node splits the feedback loop between the sender and the receiver and thus guarantees a shorter round trip time (RTT) per packet. A shorter RTT is beneficial as it ensures a quicker response time to any changes in the network and a faster adaptation by the sender to combat these changes.
Disadvantages of the method include the fact that the TCP session has to be directed through the accelerator; this means that if routing changes, so that the accelerator is no longer in the path, the connection will be broken. It also destroys the end-to-end property of the TCP ack mechanism; when the ACK is received by the sender, the packet has been stored by the accelerator, not delivered to the receiver.
Debugging[edit]
A packet sniffer, which intercepts TCP traffic on a network link, can be useful in debugging networks, network stacks, and applications that use TCP by showing the user what packets are passing through a link. Some networking stacks support the SO_DEBUG socket option, which can be enabled on the socket using setsockopt. That option dumps all the packets, TCP states, and events on that socket, which is helpful in debugging. Netstat is another utility that can be used for debugging.
Alternatives[edit]
For many applications TCP is not appropriate. One problem (at least with normal implementations) is that the application cannot access the packets coming after a lost packet until the retransmitted copy of the lost packet is received. This causes problems for real-time applications such as streaming media, real-time multiplayer games and voice over IP (VoIP) where it is generally more useful to get most of the data in a timely fashion than it is to get all of the data in order.
For historical and performance reasons, most storage area networks (SANs) use Fibre Channel Protocol (FCP) over Fibre Channel connections.
Also, for embedded systems, network booting, and servers that serve simple requests from huge numbers of clients (e.g. DNS servers) the complexity of TCP can be a problem. Finally, some tricks such as transmitting data between two hosts that are both behind NAT (using STUN or similar systems) are far simpler without a relatively complex protocol like TCP in the way.
Generally, where TCP is unsuitable, the User Datagram Protocol (UDP) is used. This provides the application multiplexing and checksums that TCP does, but does not handle streams or retransmission, giving the application developer the ability to code them in a way suitable for the situation, or to replace them with other methods like forward error correction or interpolation.
Stream Control Transmission Protocol (SCTP) is another protocol that provides reliable stream oriented services similar to TCP. It is newer and considerably more complex than TCP, and has not yet seen widespread deployment. However, it is especially designed to be used in situations where reliability and near-real-time considerations are important.
Venturi Transport Protocol (VTP) is a patented proprietary protocol that is designed to replace TCP transparently to overcome perceived inefficiencies related to wireless data transport.
TCP also has issues in high-bandwidth environments. The TCP congestion avoidance algorithm works very well for ad-hoc environments where the data sender is not known in advance. If the environment is predictable, a timing based protocol such as Asynchronous Transfer Mode (ATM) can avoid TCP’s retransmits overhead.
UDP-based Data Transfer Protocol (UDT) has better efficiency and fairness than TCP in networks that have high bandwidth-delay product.[71]
Multipurpose Transaction Protocol (MTP/IP) is patented proprietary software that is designed to adaptively achieve high throughput and transaction performance in a wide variety of network conditions, particularly those where TCP is perceived to be inefficient.
Checksum computation[edit]
TCP checksum for IPv4[edit]
When TCP runs over IPv4, the method used to compute the checksum is defined as follows:[9]
The checksum field is the 16-bit ones’ complement of the ones’ complement sum of all 16-bit words in the header and text. The checksum computation needs to ensure the 16-bit alignment of the data being summed. If a segment contains an odd number of header and text octets, alignment can be achieved by padding the last octet with zeros on its right to form a 16-bit word for checksum purposes. The pad is not transmitted as part of the segment. While computing the checksum, the checksum field itself is replaced with zeros.
In other words, after appropriate padding, all 16-bit words are added using one’s complement arithmetic. The sum is then bitwise complemented and inserted as the checksum field. A pseudo-header that mimics the IPv4 packet header used in the checksum computation is shown in the table below.
| Bit offset | 0–3 | 4–7 | 8–15 | 16–31 |
|---|---|---|---|---|
| 0 | Source address | |||
| 32 | Destination address | |||
| 64 | Zeros | Protocol | TCP length | |
| 96 | Source port | Destination port | ||
| 128 | Sequence number | |||
| 160 | Acknowledgement number | |||
| 192 | Data offset | Reserved | Flags | Window |
| 224 | Checksum | Urgent pointer | ||
| 256 | Options (optional) | |||
| 256/288+ | Data |
The source and destination addresses are those of the IPv4 header. The protocol value is 6 for TCP (cf. List of IP protocol numbers). The TCP length field is the length of the TCP header and data (measured in octets).
TCP checksum for IPv6[edit]
When TCP runs over IPv6, the method used to compute the checksum is changed:[72]
Any transport or other upper-layer protocol that includes the addresses from the IP header in its checksum computation must be modified for use over IPv6, to include the 128-bit IPv6 addresses instead of 32-bit IPv4 addresses.
A pseudo-header that mimics the IPv6 header for computation of the checksum is shown below.
| Bit offset | 0–7 | 8–15 | 16–23 | 24–31 |
|---|---|---|---|---|
| 0 | Source address | |||
| 32 | ||||
| 64 | ||||
| 96 | ||||
| 128 | Destination address | |||
| 160 | ||||
| 192 | ||||
| 224 | ||||
| 256 | TCP length | |||
| 288 | Zeros | Next header = Protocol | ||
| 320 | Source port | Destination port | ||
| 352 | Sequence number | |||
| 384 | Acknowledgement number | |||
| 416 | Data offset | Reserved | Flags | Window |
| 448 | Checksum | Urgent pointer | ||
| 480 | Options (optional) | |||
| 480/512+ | Data |
- Source address: the one in the IPv6 header
- Destination address: the final destination; if the IPv6 packet doesn’t contain a Routing header, TCP uses the destination address in the IPv6 header, otherwise, at the originating node, it uses the address in the last element of the Routing header, and, at the receiving node, it uses the destination address in the IPv6 header.
- TCP length: the length of the TCP header and data
- Next Header: the protocol value for TCP
Checksum offload [edit]
Many TCP/IP software stack implementations provide options to use hardware assistance to automatically compute the checksum in the network adapter prior to transmission onto the network or upon reception from the network for validation. This may relieve the OS from using precious CPU cycles calculating the checksum. Hence, overall network performance is increased.
This feature may cause packet analyzers that are unaware or uncertain about the use of checksum offload to report invalid checksums in outbound packets that have not yet reached the network adapter.[73] This will only occur for packets that are intercepted before being transmitted by the network adapter; all packets transmitted by the network adaptor on the wire will have valid checksums.[74] This issue can also occur when monitoring packets being transmitted between virtual machines on the same host, where a virtual device driver may omit the checksum calculation (as an optimization), knowing that the checksum will be calculated later by the VM host kernel or its physical hardware.
RFC documents[edit]
- RFC 675 – Specification of Internet Transmission Control Program, December 1974 Version
- RFC 793 – TCP v4
- RFC 1122 – includes some error corrections for TCP
- RFC 1323 – TCP Extensions for High Performance [Obsoleted by RFC 7323]
- RFC 1379 – Extending TCP for Transactions—Concepts [Obsoleted by RFC 6247]
- RFC 1948 – Defending Against Sequence Number Attacks
- RFC 2018 – TCP Selective Acknowledgment Options
- RFC 5681 – TCP Congestion Control
- RFC 6247 – Moving the Undeployed TCP Extensions RFC 1072, 1106, 1110, 1145, 1146, 1379, 1644 and 1693 to Historic Status
- RFC 6298 – Computing TCP’s Retransmission Timer
- RFC 6824 – TCP Extensions for Multipath Operation with Multiple Addresses
- RFC 7323 – TCP Extensions for High Performance
- RFC 7414 – A Roadmap for TCP Specification Documents
- RFC 9293 – Transmission Control Protocol (TCP)
See also[edit]
- Connection-oriented communication
- List of TCP and UDP port numbers (a long list of ports and services)
- Micro-bursting (networking)
- T/TCP variant of TCP
- TCP global synchronization
- TCP pacing
- Transport layer § Comparison of transport layer protocols
- WTCP a proxy-based modification of TCP for wireless networks
Notes[edit]
- ^ Experimental: see RFC 3540
- ^ a b Added to header by RFC 3168
- ^ Windows size units are, by default, bytes.
- ^ Window size is relative to the segment identified by the sequence number in the acknowledgment field.
References[edit]
- ^ Vinton G. Cerf; Robert E. Kahn (May 1974). «A Protocol for Packet Network Intercommunication» (PDF). IEEE Transactions on Communications. 22 (5): 637–648. doi:10.1109/tcom.1974.1092259. Archived from the original (PDF) on March 4, 2016.
- ^ Bennett, Richard (September 2009). «Designed for Change: End-to-End Arguments, Internet Innovation, and the Net Neutrality Debate» (PDF). Information Technology and Innovation Foundation. p. 11. Retrieved 11 September 2017.
- ^ V. Cerf; Y. Dalal; C. Sunshine (December 1974). SPECIFICATION OF INTERNET TRANSMISSION CONTROL PROGRAM. Network Working Group. doi:10.17487/RFC0698. RFC 698. Obsolete. Obsoleted by RFC 7805. NIC 2. INWG 72.
- ^ «Robert E Kahn — A.M. Turing Award Laureate». amturing.acm.org.
- ^ «Vinton Cerf — A.M. Turing Award Laureate». amturing.acm.org.
- ^ a b c d e f g h i Comer, Douglas E. (2006). Internetworking with TCP/IP: Principles, Protocols, and Architecture. Vol. 1 (5th ed.). Prentice Hall. ISBN 978-0-13-187671-2.
- ^ «TCP (Transmission Control Protocol)». Retrieved 2019-06-26.
- ^ J. Postel, ed. (September 1981). INTERNET PROTOCOL — DARPA INTERNET PROGRAM PROTOCOL SPECIFICATION. IETF. doi:10.17487/RFC0791. STD 5. RFC 791. IEN 128, 123, 111, 80, 54, 44, 41, 28, 26. Internet Standard. Obsoletes RFC 760. Updated by RFC 1349, 2474 and 6864.
- ^ a b c d W. Eddy, ed. (August 2022). Transmission Control Protocol (TCP). Internet Engineering Task Force. doi:10.17487/RFC9293. ISSN 2070-1721. STD 7. RFC 9293. Internet Standard. Obsoletes RFC 793, 879, 2873, 6093, 6429, 6528 and 6691. Updates RFC 1011, 1122 and 5961.
- ^ TCP Extensions for High Performance. sec. 2.2. RFC 1323.
- ^ a b S. Floyd; J. Mahdavi; M. Mathis; A. Romanow (October 1996). TCP Selective Acknowledgment Options. IETF TCP Large Windows workgroup. doi:10.17487/RFC2018. RFC 2018. Proposed Standard. Obsoletes RFC 1072.
- ^ «RFC 1323, TCP Extensions for High Performance, Section 3.2».
- ^ «Transmission Control Protocol (TCP) Parameters: TCP Option Kind Numbers». IANA.
- ^ W. Eddy, ed. (August 2022). Transmission Control Protocol (TCP). Internet Engineering Task Force. doi:10.17487/RFC9293. ISSN 2070-1721. STD 7. RFC 9293. Internet Standard. sec. 3.3.2.
- ^ Kurose, James F. (2017). Computer networking : a top-down approach. Keith W. Ross (7th ed.). Harlow, England. p. 286. ISBN 978-0-13-359414-0. OCLC 936004518.
- ^ Tanenbaum, Andrew S. (2003-03-17). Computer Networks (Fourth ed.). Prentice Hall. ISBN 978-0-13-066102-9.
- ^ R. Braden, ed. (October 1989). Requirements for Internet Hosts — Communication Layers. Network Working Group. doi:10.17487/RFC1122. STD 3. RFC 1122. Internet Standard. sec. 4.2.2.13.
- ^ «TCP Definition». Retrieved 2011-03-12.
- ^ Mathis; Mathew; Semke; Mahdavi; Ott (1997). «The macroscopic behavior of the TCP congestion avoidance algorithm». ACM SIGCOMM Computer Communication Review. 27 (3): 67–82. CiteSeerX 10.1.1.40.7002. doi:10.1145/263932.264023. S2CID 1894993.
- ^ a b V. Paxson; M. Allman; J. Chu; M. Sargent (June 2011). Computing TCP’s Retransmission Timer. Internet Engineering Task Force. doi:10.17487/RFC6298. ISSN 2070-1721. RFC 6298. Proposed Standard. Obsoletes RFC 2988. Updates RFC 1122.
- ^ Stone; Partridge (2000). «When The CRC and TCP Checksum Disagree». ACM SIGCOMM Computer Communication Review: 309–319. CiteSeerX 10.1.1.27.7611. doi:10.1145/347059.347561. ISBN 978-1581132236. S2CID 9547018.
- ^ M. Allman; V. Paxson; E. Blanton (September 2009). TCP Congestion Control. IETF. doi:10.17487/RFC5681. RFC 5681. Draft Standard. Obsoletes RFC 2581.
- ^ D. Borman; B. Braden; V. Jacobson (September 2014). R. Scheffenegger (ed.). TCP Extensions for High Performance. Internet Engineering Task Force. doi:10.17487/RFC7323. ISSN 2070-1721. RFC 7323. Proposed Standard. Obsoletes RFC 1323.
- ^ R. Braden, ed. (October 1989). Requirements for Internet Hosts — Communication Layers. Network Working Group. doi:10.17487/RFC1122. STD 3. RFC 1122. Internet Standard. Updated by RFC 1349, 4379, 5884, 6093, 6298, 6633, 6864, 8029 and 9293.
- ^ «TCP window scaling and broken routers». LWN.net.
- ^ RFC 3522
- ^ «IP sysctl». Linux Kernel Documentation. Retrieved 15 December 2018.
- ^ Wang, Eve. «TCP timestamp is disabled». Technet — Windows Server 2012 Essentials. Microsoft. Archived from the original on 2018-12-15. Retrieved 2018-12-15.
- ^ David Murray; Terry Koziniec; Sebastian Zander; Michael Dixon; Polychronis Koutsakis (2017). «An Analysis of Changing Enterprise Network Traffic Characteristics» (PDF). The 23rd Asia-Pacific Conference on Communications (APCC 2017). Retrieved 3 October 2017.
- ^ Gont, Fernando (November 2008). «On the implementation of TCP urgent data». 73rd IETF meeting. Retrieved 2009-01-04.
- ^ Peterson, Larry (2003). Computer Networks. Morgan Kaufmann. p. 401. ISBN 978-1-55860-832-0.
- ^ Richard W. Stevens (November 2011). TCP/IP Illustrated. Vol. 1, The protocols. Addison-Wesley. pp. Chapter 20. ISBN 978-0-201-63346-7.
- ^ «Security Assessment of the Transmission Control Protocol (TCP)» (PDF). Archived from the original on March 6, 2009. Retrieved 2010-12-23.
{{cite web}}: CS1 maint: bot: original URL status unknown (link) - ^ Security Assessment of the Transmission Control Protocol (TCP)
- ^ Jakob Lell. «Quick Blind TCP Connection Spoofing with SYN Cookies». Retrieved 2014-02-05.
- ^ «Some insights about the recent TCP DoS (Denial of Service) vulnerabilities» (PDF).
- ^ «Exploiting TCP and the Persist Timer Infiniteness».
- ^ «PUSH and ACK Flood». f5.com.
- ^ «Laurent Joncheray, Simple Active Attack Against TCP, 1995″.
- ^ John T. Hagen; Barry E. Mullins (2013). TCP veto: A novel network attack and its application to SCADA protocols. Innovative Smart Grid Technologies (ISGT), 2013 IEEE PES. pp. 1–6. doi:10.1109/ISGT.2013.6497785. ISBN 978-1-4673-4896-6. S2CID 25353177.
- ^ «TCP Interactive». www.medianet.kent.edu.
- ^ J. Iyengar; C. Raiciu; S. Barre; M. Handley; A. Ford (March 2011). Architectural Guidelines for Multipath TCP Development. Internet Engineering Task Force (IETF). doi:10.17487/RFC6182. RFC 6182. Informational.
- ^ Alan Ford; C. Raiciu; M. Handley; O. Bonaventure (January 2013). TCP Extensions for Multipath Operation with Multiple Addresses. Internet Engineering Task Force. doi:10.17487/RFC6824. ISSN 2070-1721. RFC 6824. Experimental. Obsoleted by RFC 8624.
- ^ Raiciu; Barre; Pluntke; Greenhalgh; Wischik; Handley (2011). «Improving datacenter performance and robustness with multipath TCP». ACM SIGCOMM Computer Communication Review. 41 (4): 266. CiteSeerX 10.1.1.306.3863. doi:10.1145/2043164.2018467. Archived from the original on 2020-04-04. Retrieved 2011-06-29.
- ^ «MultiPath TCP — Linux Kernel implementation».
- ^ Raiciu; Paasch; Barre; Ford; Honda; Duchene; Bonaventure; Handley (2012). «How Hard Can It Be? Designing and Implementing a Deployable Multipath TCP». Usenix NSDI: 399–412.
- ^ Bonaventure; Seo (2016). «Multipath TCP Deployments». IETF Journal.
- ^ Michael Kerrisk (2012-08-01). «TCP Fast Open: expediting web services». LWN.net.
- ^ Yuchung Cheng; Jerry Chu; Sivasankar Radhakrishnan & Arvind Jain (December 2014). «TCP Fast Open». IETF. Retrieved 10 January 2015.
- ^ Mathis, Matt; Dukkipati, Nandita; Cheng, Yuchung (May 2013). «RFC 6937 — Proportional Rate Reduction for TCP». Retrieved 6 June 2014.
- ^ Grigorik, Ilya (2013). High-performance browser networking (1. ed.). Beijing: O’Reilly. ISBN 978-1449344764.
- ^ W. Simpson (January 2011). TCP Cookie Transactions (TCPCT). IETF. doi:10.17487/RFC6013. ISSN 2070-1721. RFC 6013. Obsolete. Obsoleted by RFC 7805.
- ^ A. Zimmermann; W. Eddy; L. Eggert (April 2016). Moving Outdated TCP Extensions and TCP-Related Documents to Historic or Informational Status. IETF. doi:10.17487/RFC7805. ISSN 2070-1721. RFC 7805. Informational. Obsoletes RFC 675, 721, 761, 813, 816, 879, 896 and 6013. Updates RFC 7414, 4291, 4338, 4391, 5072 and 5121.
- ^ a b «TCP performance over CDMA2000 RLP». Archived from the original on 2011-05-03. Retrieved 2010-08-30.
- ^ Muhammad Adeel & Ahmad Ali Iqbal (2004). TCP Congestion Window Optimization for CDMA2000 Packet Data Networks. International Conference on Information Technology (ITNG’07). pp. 31–35. doi:10.1109/ITNG.2007.190. ISBN 978-0-7695-2776-5. S2CID 8717768.
- ^ Trammell & Kuehlewind 2019, p. 6.
- ^ Hardie 2019, p. 3.
- ^ Fairhurst & Perkins 2021, 3. Research, Development, and Deployment.
- ^ Hardie 2019, p. 8.
- ^ Thomson & Pauly 2021, 2.3. Multi-party Interactions and Middleboxes.
- ^ Thomson & Pauly 2021, A.5. TCP.
- ^ Papastergiou et al. 2017, p. 620.
- ^ Edeline & Donnet 2019, p. 175-176.
- ^ Raiciu et al. 2012, p. 1.
- ^ Hesmans et al. 2013, p. 1.
- ^ Rybczyńska 2020.
- ^ Papastergiou et al. 2017, p. 621.
- ^ Corbet 2015.
- ^ Briscoe et al. 2006, p. 29-30.
- ^
Yunhong Gu, Xinwei Hong, and Robert L. Grossman.
«An Analysis of AIMD Algorithm with Decreasing Increases».
2004. - ^ S. Deering; R. Hinden (July 2017). Internet Protocol, Version 6 (IPv6) Specification. IETF. doi:10.17487/RFC8200. STD 86. RFC 8200. Internet Standard. Obsoletes RFC 2460.
- ^ «Wireshark: Offloading».
Wireshark captures packets before they are sent to the network adapter. It won’t see the correct checksum because it has not been calculated yet. Even worse, most OSes don’t bother initialize this data so you’re probably seeing little chunks of memory that you shouldn’t. New installations of Wireshark 1.2 and above disable IP, TCP, and UDP checksum validation by default. You can disable checksum validation in each of those dissectors by hand if needed.
- ^ «Wireshark: Checksums».
Checksum offloading often causes confusion as the network packets to be transmitted are handed over to Wireshark before the checksums are actually calculated. Wireshark gets these «empty» checksums and displays them as invalid, even though the packets will contain valid checksums when they leave the network hardware later.
Bibliography[edit]
- Trammell, Brian; Kuehlewind, Mirja (April 2019). The Wire Image of a Network Protocol. doi:10.17487/RFC8546. RFC 8546.
- Hardie, Ted, ed. (April 2019). Transport Protocol Path Signals. doi:10.17487/RFC8558. RFC 8558.
- Fairhurst, Gorry; Perkins, Colin (July 2021). Considerations around Transport Header Confidentiality, Network Operations, and the Evolution of Internet Transport Protocols. doi:10.17487/RFC9065. RFC 9065.
- Thomson, Martin; Pauly, Tommy (December 2021). Long-Term Viability of Protocol Extension Mechanisms. doi:10.17487/RFC9170. RFC 9170.
- Hesmans, Benjamin; Duchene, Fabien; Paasch, Christoph; Detal, Gregory; Bonaventure, Olivier (2013). Are TCP extensions middlebox-proof?. HotMiddlebox ’13. doi:10.1145/2535828.2535830.
- Corbet, Jonathan (8 December 2015). «Checksum offloads and protocol ossification». LWN.net.
- Briscoe, Bob; Brunstrom, Anna; Petlund, Andreas; Hayes, David; Ros, David; Tsang, Ing-Jyh; Gjessing, Stein; Fairhurst, Gorry; Griwodz, Carsten; Welzl, Michael (2016). «Reducing Internet Latency: A Survey of Techniques and Their Merits». IEEE Communications Surveys & Tutorials. 18 (3): 2149–2196. doi:10.1109/COMST.2014.2375213. hdl:2164/8018. S2CID 206576469.
- Papastergiou, Giorgos; Fairhurst, Gorry; Ros, David; Brunstrom, Anna; Grinnemo, Karl-Johan; Hurtig, Per; Khademi, Naeem; Tüxen, Michael; Welzl, Michael; Damjanovic, Dragana; Mangiante, Simone (2017). «De-Ossifying the Internet Transport Layer: A Survey and Future Perspectives». IEEE Communications Surveys & Tutorials. doi:10.1109/COMST.2016.2626780.
- Edeline, Korian; Donnet, Benoit (2019). A Bottom-Up Investigation of the Transport-Layer Ossification. 2019 Network Traffic Measurement and Analysis Conference (TMA). doi:10.23919/TMA.2019.8784690.
- Rybczyńska, Marta (13 March 2020). «A QUIC look at HTTP/3». LWN.net.
Further reading[edit]
- Stevens, W. Richard (1994-01-10). TCP/IP Illustrated, Volume 1: The Protocols. Addison-Wesley Pub. Co. ISBN 978-0-201-63346-7.
- Stevens, W. Richard; Wright, Gary R (1994). TCP/IP Illustrated, Volume 2: The Implementation. ISBN 978-0-201-63354-2.
- Stevens, W. Richard (1996). TCP/IP Illustrated, Volume 3: TCP for Transactions, HTTP, NNTP, and the UNIX Domain Protocols. ISBN 978-0-201-63495-2.**
External links[edit]
- Oral history interview with Robert E. Kahn
- IANA Port Assignments
- IANA TCP Parameters
- John Kristoff’s Overview of TCP (Fundamental concepts behind TCP and how it is used to transport data between two endpoints)
- Checksum example
- TCP tutorial
[note 2][122]
RxMon.exe radacct port,[when?] RADIUS accounting protocol. Enabled for compatibility reasons by default on Cisco[citation needed] and Juniper Networks RADIUS servers.[141] Official port is 1813. TCP port 1646 must not be used.[142] ms-streaming) radius radius-acct serv-hm connection The TCP port is now used for: IBM WebSphere MQ Workflow
ajp13)[citation needed] mongod) and routing service (mongos)[379] Миллион одновременных соединений

Я слышал ошибочные утверждения о том, что сервер может принять только 65 тысяч соединений или что сервер всегда использует по одному порту на каждое принятое подключение. Вот как они примерно выглядят:
Адрес TCP/IP поддерживает только 65000 подключений, поэтому придётся назначить этому серверу примерно 30000 IP-адресов.
Существует 65535 номеров TCP-портов, значит ли это, что к TCP-серверу может подключиться не более 65535 клиентов? Можно решить, что это накладывает строгое ограничение на количество клиентов, которые может поддерживать один компьютер/приложение.
Если есть ограничение на количество портов, которые может иметь одна машина, а сокет можно привязать только к неиспользуемому номеру порта, как с этим справляются серверы, имеющие чрезвычайно большое количество запросов (больше, чем максимальное количество портов)? Эта проблема решается распределением системы, то есть кучей серверов на множестве машин?
Поэтому я написал эту статью, чтобы развеять данный миф с трёх сторон:
- Мессенджер WhatsApp и веб-фреймворк Phoenix, построенный на основе Elixir, уже продемонстрировали миллионы подключений, прослушивающих один порт.
- Теоретические возможности на основе протокола TCP/IP.
- Простой эксперимент с Java, который может провести на своей машине любой, если его всё ещё не убедили мои слова.
Если вы не хотите изучать подробности, то перейдите в раздел «Итоги» в конце статьи.
Эксперименты
Фреймворк Phoenix достиг 2000000 одновременных подключений websocket. В статье разработчики демонстрируют приложение для чата, в котором симулируются 2 миллиона пользователей, а для пересылки сообщений на всех пользователей требуется 1 секунда. Они также рассказывают подробности о технических сложностях, с которыми они столкнулись в фреймворке, пытаясь добиться этого рекорда. Некоторые из изложенных в их статье идей я использовал для написания своего поста, например, назначение множественных IP, чтобы преодолеть ограничение в 65 тысяч клиентских соединений.
WhatsApp тоже достиг показателя в 2000000 подключений. К сожалению, разработчики почти не делятся подробностями. Они рассказали только о «железе» и операционной системе.
Теоретический максимум
Кто-то думает, что предел равен 216=65536, потому что это все порты, доступные по спецификации TCP. Этот предел справедлив для одного клиента создающего исходящие соединения с одной парой IP и порта. Например, мой ноутбук сможет создать только 65536 соединений с 172.217.13.174:443 (google.com:443), но, вероятно, Google заблокирует меня ещё до того, как я установлю 65 тысяч соединений. Итак, если вам нужна связь между двумя машинами с более чем 65 тысяч одновременных подключений, то клиенту нужно будет подключиться со второго IP-адреса или сервер должен сделать доступным второй порт.
У сервера, слушающего порт, каждое входящее подключение НЕ забирает порт сервера. Сервер может использовать только один порт, который он слушает. Кроме того, соединения будут поступать от нескольких IP-адресов. В лучшем случае сервер сможет прослушивать все IP-адреса, поступающие со всех портов.
Каждое TCP-подключение уникальным образом задаётся следующими параметрами:
- 32-битным исходного IP (IP-адресом, с которого поступает подключение);
- 16-битным исходным портом (портом исходного IP-адреса, с которого поступает подключение);
- 32-битным IP получателя (IP-адресом, к которому выполняется подключение);
- 16-битным портом получателя (портом IP-адреса получателя, к которому выполняется подключение).
Значит, теоретический предел, который может поддерживать сервер на одном порту — это 248, то есть около 1 квадриллиона, потому что:
- Сервер различает подключения от IP-адресов клиентов и исходных портов;
- [количество исходных IP-адресов]x[количество исходных портов];
- 32 бита на адрес и 16 бит на порт;
- Соединяем всё вместе: 232 x 216 = 248;
- Это примерно равно квадриллиону (log(248)/log(10)=14,449)!
Практический предел
Чтобы определить оптимистический практический предел, я провёл эксперименты, пытаясь открыть как можно больше TCP-соединений и заставить сервер отправлять и получать сообщение в каждом соединении. По сравнению с нагрузкой Phoenix или WhatsApp эта нагрузка совершенно непрактична, однако её проще реализовать, если вы захотите попробовать сами. Чтобы провести эксперимент, нужно справиться с тремя трудностями: операционной системой, JVM и протоколом TCP/IP.
Эксперимент
Если вам интересен исходный код, его можно изучить здесь.
Псевдокод выглядит так:
Поток 1:
открыть сокет сервера
for i from 1 to 1 000 000:
принять входящее подключение
for i from 1 to 1 000 000
отправить число i на сокет i
for i from 1 to 1 000 000
получить число j на сокете i
assert i == j
Поток 2:
for i from 1 to 1 000 000:
открыть сокет клиента серверу
for i from 1 to 1 000 000:
получить число j на сокете i
assert i == j
for i from 1 to 1 000 000
отправить число i на сокет i Машины
В качестве машин я использовал свой Mac:
2.5 GHz Quad-Core Intel Core i7 16 GB 1600 MHz DDR3
и свой десктоп с Linux:
AMD FX(tm)-6300 Six-Core Processor 8GiB 1600 MHz
Дескрипторы файлов
Первым делом нам придётся сразиться с операционной системой. Параметры по умолчанию сильно ограничивают дескрипторы файлов. Вы увидите подобную ошибку:
Exception in thread "main" java.lang.ExceptionInInitializerError at java.base/sun.nio.ch.SocketDispatcher.close(SocketDispatcher.java:70) at java.base/sun.nio.ch.NioSocketImpl.lambda$closerFor$0(NioSocketImpl.java:1203) at java.base/jdk.internal.ref.CleanerImpl$PhantomCleanableRef.performCleanup(CleanerImpl.java:178) at java.base/jdk.internal.ref.PhantomCleanable.clean(PhantomCleanable.java:133) at java.base/sun.nio.ch.NioSocketImpl.tryClose(NioSocketImpl.java:854) at java.base/sun.nio.ch.NioSocketImpl.close(NioSocketImpl.java:906) at java.base/java.net.SocksSocketImpl.close(SocksSocketImpl.java:562) at java.base/java.net.Socket.close(Socket.java:1585) at Main.main(Main.java:123) Caused by: java.io.IOException: Too many open files at java.base/sun.nio.ch.FileDispatcherImpl.init(Native Method) at java.base/sun.nio.ch.FileDispatcherImpl.<clinit>(FileDispatcherImpl.java:38) ... 9 more
Каждому сокету сервера нужно два дескриптора файлов:
- Буфер для отправки.
- Буфер для получения.
То же относится и к клиентским подключениям. Поэтому для запуска этого эксперимента на одной машине потребуется:
- 1000000 подключений для клиента;
- 1000000 подключений для сервера;
- По 2 дескриптора файлов на каждое подключение;
- = 4000000 дескрипторов файлов.
На Mac с bigSur 11.4 увеличить ограничение на дескрипторы файлов можно так:
sudo sysctl kern.maxfiles=2000000 kern.maxfilesperproc=2000000 kern.maxfiles: 49152 -> 2000000 kern.maxfilesperproc: 24576 -> 2000000 sysctl -a | grep maxfiles kern.maxfiles: 2000000 kern.maxfilesperproc: 1000000 ulimit -Hn 2000000 ulimit -Sn 2000000
как рекомендовано в этом ответе на StackOverflow.
В Ubuntu 20.04 быстрее всего будет сделать так:
sudo su # 2^25 должно быть более чем достаточно sysctl -w fs.nr_open=33554432 fs.nr_open = 33554432 ulimit -Hn 33554432 ulimit -Sn 33554432
Пределы дескрипторов файлов Java
Мы разобрались с операционной системой, но JVM тоже не понравится то, что мы будем делать в этом эксперименте. При его проведении мы получим такую же или похожую трассировку стека.
В этом ответе на StackOverflow указано решение в виде флага JVM:
-XX:-MaxFDLimit: отключает попытки установки программного ограничения на аппаратное ограничение количества открытых дескрипторов файлов. По умолчанию эта опция включена на всех платформах, но в Windows игнорируется. Отключать её стоит только в Mac OS, где её использование накладывает ограничение в 10240, что меньше, чем действительный максимум системы.
java -XX:-MaxFDLimit Main 6000
Как написано в этой цитате из документации Java, отключить флаг нужно только на Mac.
В Ubuntu мне удалось провести эксперимент без этого флага.
Исходные порты
Но эксперимент всё равно не работает. Я нашёл следующую трассировку стека:
Exception in thread "main" java.net.BindException: Can't assign requested
address
at java.base/sun.nio.ch.Net.bind0(Native Method)
at java.base/sun.nio.ch.Net.bind(Net.java:555)
at java.base/sun.nio.ch.Net.bind(Net.java:544)
at java.base/sun.nio.ch.NioSocketImpl.bind(NioSocketImpl.java:643)
at
java.base/java.net.DelegatingSocketImpl.bind(DelegatingSocketImpl.java:94)
at java.base/java.net.Socket.bind(Socket.java:682)
at java.base/java.net.Socket.<init>(Socket.java:506)
at java.base/java.net.Socket.<init>(Socket.java:403)
at Main.main(Main.java:137) Последняя битва нам предстоит со спецификацией TCP/IP. На данный момент мы зафиксировали адрес сервера, порт сервера и IP-адрес клиента. При этом у нас остаётся лишь 16 бит свободы, то есть мы можем открыть только 65 тысяч соединений.
Нашему эксперименту этого совершенно недостаточно. Мы не можем поменять ни IP сервера, ни порт сервера, потому что это проблема, которую мы исследуем в этом эксперименте. Остаётся возможность изменить IP клиента, что даёт нам доступ ещё к 32 битам. В результате мы обойдём ограничение, консервативно присваивая клиентский IP-адрес для каждых 5000 клиентских подключений. Ту же технику использовали в эксперименте с Phoenix.
В bigSur 11.4 можно добавить серию фальшивых адресов замыкания на себя (loopback address) следующей командой:
for i in `seq 0 200`; do sudo ifconfig lo0 alias 10.0.0.$i/8 up ; done
Чтобы протестировать работу IP-адресов, их можно попинговать:
for i in `seq 0 200`; do ping -c 1 10.0.0.$i ; done
Чтобы удалить, используем такую команду:
for i in `seq 0 200`; do sudo ifconfig lo0 alias 10.0.0.$i ; done
В Ubuntu 20.04 вместо этого потребуется использовать инструмент ip:
for i in `seq 0 200`; do sudo ip addr add 10.0.0.$i/8 dev lo; done
Чтобы удалить, используем команду:
for i in `seq 0 200`; do sudo ip addr del 10.0.0.$i/8 dev lo; done
Результаты
На Mac мне удалось достигнуть 80000 соединений. Однако спустя несколько минут после завершения эксперимента мой бедный Mac каждый раз загадочным образом вылетал без отчётов о сбое в /Library/Logs/DiagnosticReports, поэтому я не смог диагностировать, что случилось.
Буферы TCP отправки и получения на моём Mac имеют размер 131072 байта:
sysctl net | grep tcp | grep -E '(recv)|(send)' net.inet.tcp.sendspace: 131072 net.inet.tcp.recvspace: 131072
Поэтому, возможно, это произошло из-за того, что я использовал 80000 подключений *131072 байт на буфер * 2 буфера ввода и вывода * 2 клиентских и серверных подключения байт, что равно примерно 39 ГБ виртуальной памяти. Или, может быть, Mac OS не нравится, что я использую 80000*2*2=320000 дескрипторов файлов. К сожалению, я незнаком с отладкой на Mac без отчётов о сбоях, поэтому если кто-то знает информацию по теме, напишите мне.
В Linux мне удалось достичь 840000 подключений! Однако в процессе проведения эксперимента для регистрации перемещения мыши по экрану требовалось несколько секунд. При увеличении количества подключений Linux начинал зависать и переставал реагировать.
Чтобы понять, какой ресурс вызывает проблемы, я воспользовался sysstat. Посмотреть на сгенерированные sysstat графики можно здесь.
Чтобы sysstat фиксировал статистику по всему оборудованию, а затем генерировал графики, я использовал такую команду:
sar -o out.840000.sar -A 1 3600 2>&1 > /dev/null & sadf -g out.840000.sar -- -w -r -u -n SOCK -n TCP -B -S -W > out.840000.svg
Любопытные факты:
MBmemfreeпоказывал меньше всего памяти, 96 МБ;MBavailпоказывал 1587 МБ;MBmemusedпоказывал всего 1602 МБ (19,6% от моих 8 ГБ);MBswpusedна пике показывал 1086 МБ (несмотря на то, что свободная память ещё была);- 1680483 сокета (840 тысяч серверных сокетов и 840 тысяч клиентских подключений плюс то, что работало на моём десктопе);
- Спустя несколько секунд после начала эксперимента операционная система решила задействовать swap, хотя у меня ещё была память.
Чтобы определить стандартный размер буферов отправки и получения в Linux, можно использовать такую команду:
# минимальное, стандартное и максимальное значения размера памяти (в байтах) cat /proc/sys/net/ipv4/tcp_rmem 4096 131072 6291456 cat /proc/sys/net/ipv4/tcp_wmem 4096 16384 4194304 sysctl net.ipv4.tcp_rmem net.ipv4.tcp_rmem = 4096 131072 6291456 sysctl net.ipv4.tcp_wmem net.ipv4.tcp_wmem = 4096 16384 4194304
Для поддержания всех подключений мне бы потребовалось 247 ГБ виртуальной памяти!
131072 байта для получения 16384 для записи (131072+16384)*2*840000 =247 ГБ виртуальной памяти
Я подозреваю, что буферы запрашивались, но поскольку из каждого нужно всего по 4 байта, использовалась лишь небольшая доля буферов. Даже если бы загрузил 1 страницу памяти, потому что мне нужно записать лишь 4 байта для записи integer в буфер:
getconf PAGESIZE 4096 Размер страницы 4096 байт (4096+4096)*2*840000 =13 ГБ
то использовалось бы 13 ГБ, задействуя 2*840000 страниц памяти. Понятия не имею, как всё это работает без сбоев! Однако мне вполне хватает 840000 одновременных подключений.
Вы можете улучшить мой результат, если у вас есть больше памяти или вы ещё сильнее оптимизируете параметры операционной системы, например, уменьшив размеры буферов TCP.
Итоги
- Фреймворку Phoenix удалось достичь 2 000 000 подключений.
- WhatsApp удалось достичь 2 000 000 подключений.
- Теоретический предел примерно равен 1 квадриллиону (1 000 000 000 000 000).
- У вас закончатся исходные порты (всего 216).
- Это можно исправить, добавив клиентские IP-адреса замыкания на себя.
- У вас закончатся дескрипторы файлов.
- Это можно исправить, изменив ограничения на дескрипторы файлов операционной системы.
- Java тоже ограничит количество дескрипторов файлов.
- Это можно исправить, добавив аргумент JVM
-XX:MaxFDLimit. - На моём Mac с 16 ГБ практический предел составил 80 000 подключений.
- На моём Linux-десктопе с 8 ГБ практический предел составил 840 000 подключений.
Quick Definition of TCP: Transmission Control Protocol (TCP) is a global communication standard that devices use to reliably transmit data. TCP is defined by being connection-oriented, which means that both the client and the server have to be established before the data gets sent. This means the data is reliable, ordered and error-checked in transit. It is one of the main protocols of the Internet protocol suite — and the entire suite is often referred to as TCP/IP.
Quick Definition of TCP Ports: A «port» is a logical distinction in computer networking. Ports are numbered and used as global standards to identify specific processes or types of network services.
Much like before shipping something to a foreign country, you’d agree where you’d be shipping out of and where you’d have it arriving, TCP ports allow for standardized communication between devices. One device can receive information for many different processes and services, and which port the information flows on helps to keep it organized.
An Overview of TCP Ports [VIDEO]
In this video, Tim Warner covers what TCP ports are as well as where and how TCP port numbers are used. He further describes how you can use the netstat command-line tool to find port use information. He also explains how, on Windows computers, you can use a free GUI-based tool called TCPView to better view and work with this information.
How Do TCP and TCP Ports Work?
Transmission Control Protocol is a key component of the TCP/IP protocol stack. TCP is a connection-oriented protocol that requires a connection or a circuit between the source sending computer and the destination one. TCP is one of the two main ways to transmit data in a TCP/IP network. UDP, which is a best-effort connectionless protocol, is the other one.
For devices to communicate via TCP, they use TCP ports. Generally, a TCP port represents an application or service-specific endpoint identifier.
Think of opening a web browser. When you type in «CBTNuggets.com», your browser translates that to «http://www.cbtnuggets.com». And with that, you’re specifying the hypertext transfer protocol — and hopefully, you get the page without issue. That happens because CBT Nuggets’ web server aka its HTTP server is listening for incoming connections on a particular port address.
The well-known port for HTTP is 80. By contrast, you might download some software from ftp.microsoft.com, their FTP server is going to be listening on the well-known Port 23. And so forth. Protip: If you’re planning to earn an IT certification exam, you may need to have many of the most common TCP ports memorized.
How Many TCP Ports are There?
A TCP port is a 16-bit, unsigned value, so there’s a finite number of TCP ports available in the world. Specifically, there are 65,535 available TCP ports.
You’ve probably heard that the world is moving from IPv4 to IPv6 due to address depletion. It’s also entirely likely that the time will come when we’ll have to expand the port range to accommodate additional services.
That said, the first 1,024 TCP ports are called well-known port numbers, and they’re agreed upon among technology vendors. So if you and I were to go into business and sell a really nice FTP client software, we’d agree to work with the standard, well-known FTP port numbers.
How Do Sockets Work with TCP Connections?
A socket allows for a connection to another system that’s already running some TCP server software. A socket takes a combination of an IP address and a port number. That means a single host can host multiple instances of the same service by using different port numbers.
For instance, we can set up a web server that has «Site 1» listening on the default port of 80 and another web server. That is to say another website on the same server with the same IP address, «Site 2», but listening on Port 8080.
Where and How Do We Use Port Numbers?
One place is during server application configuration. Enterprise apps like Oracle, SQL, SharePoint, all require you to set up services on discrete port numbers. Which is also why working with your network administrator to allow for that traffic to flow on those port IDs are important. Firewalls monitor ports to keep systems secure.
Service addressing is another way to use port numbers. Once we install our enterprise application, we advertise the service using, generally speaking, a hostname and the port number. For example, «http://cbtnuggets:1988». We wouldn’t have to do that if it were a well-known port. If it’s well known, we can leave it off.
We use port numbers for troubleshooting purposes. Specifically, we can troubleshoot malware and identify rogue processes.
Firewall configuration often uses rules that denote both aspects of a socket. You might create allowances or traffic blocks based on IP addresses, port numbers, or both.
How to View TCP Connections on Your Machine
Regardless of your OS, you can always get to the netstat command line tool, although the specific parameters you use will depend on your OS. In Windows, start with a command prompt and type:
This will output a table of all current TCP connections on the system. Unfortunately, you can’t do all that much besides looking at it.
There’s another option, though, and that’s to type:
This outputs a lot more data that’s much more useful. This includes all the parameters.
What’s a Good Tool for Viewing TCP Information?
If you’re working on a Windows machine, TCPView.exe is strongly recommended. A Microsoft property now, it was originally developed by Mark Russinovich. There’s also a command line version of the tool called TCPVcon that’s also free.
What’s great about TCPView is its graphical interface. And the interface is more than just a netstat query on steroids, there’s a lot of context and information in its interface.
Running TCPView, you may discover that you have quite a lot more running on your system in terms of remote connections than you might have otherwise been aware. That’s one of the reasons TCPView is an excellent way to diagnose rogue processes. It could be a trojan horse, some sort of backdoor administrative application that phones home. You can easily identify those tools, by taking a look.
Don’t be surprised if you see many applications running with processes going like Outlook, Chrome, or Dropbox. If you right-click one of these items that’s listed, you’ll get a specific ID of the image or the executable program that’s running. You can also end the process — terminate it from there — by right-clicking and pressing «close application». You can right-click a process and do a WHOIS lookup. There’s a lot of good things to do in TCPView and you should play around with it.
The bottom line with TCPView is that by using it you can see that for each process that you have running on your system, you can see at a glance if it’s TCP or UDP. And you can see the local and remote port. You’ll see that UDP doesn’t have remote ports, that’s because UDP is a connectionless protocol and doesn’t require an end-to-end circuit like TCP does. Which is why TCP tells us on this interface where we’re connected, both locally and to a remote system.
Wrapping Up
TCP is an important concept for any network professional to understand. It’s one of the tools that has made our modern digital age possible. All this information about understanding TCP/IP lends itself to learning much more about IT professions. If you’re looking for more detail, check out our CompTIA A+ training.
- Порт (TCP/UDP)
-
Сетевой порт — параметр протоколов UDP, определяющий назначение пакетов данных в формате
Это условное число от 0 до 65535, позволяющие различным программам, выполняемым на одном хосте, получать данные независимо друг от друга (предоставляют так называемые сетевые сервисы). Каждая программа обрабатывает данные, поступающие на определённый порт (иногда говорят, что программа «слушает» этот номер порта).
Обычно за некоторыми распространёнными сетевыми протоколами закреплены стандартные номера портов (например, веб-серверы обычно принимают данные по протоколу TCP-порт 80), хотя в большинстве случаев программа может использовать любой порт.
Содержание
- 1 Номера портов
- 1.1 Краткий список номеров портов
- 2 Порты отправителя и получателя
- 3 Использование портов для различных кодировок
- 4 Ссылки
- 5 Примечания
Номера портов
Порты TCP не пересекаются с портами UDP. То есть, порт 1234 протокола TCP не будет мешать обмену по UDP через порт 1234.
Ряд номеров портов стандартизован (см. Список портов TCP и UDP). Список поддерживается некоммерческой организацией операционных систем прослушивание портов с номерами 0—1023 (почти все из которых зарегистрированы) требует особых привилегий. Каждый из остальных портов может быть захвачен первым запросившим его процессом. Однако, зарегистрировано номеров намного больше, чем 1023.
Краткий список номеров портов
Подразумевается использование протокола TCP там, где не оговорено иное.
Порты отправителя и получателя
На самом деле, TCP- или UDP-пакеты всегда содержат два поля номера порта: отправителя и получателя. Тип обслуживающей программы определяется портом получателя поступающих запросов, и этот же номер является портом отправителя ответов. «Обратный» порт (порт отправителя запросов, он же порт получателя ответов) при подключении по TCP определяется клиентом произвольно (хотя номера меньше 1024 и уже занятых портов не назначаются), и для пользователя интереса не представляет. Использование обратных номеров портов в UDP зависит от реализации.
Использование портов для различных кодировок
Разные порты веб-сервера могут использоваться для поддержки различных кодировок текста, отправляемого браузеру посетителя. При этом по стандартному порту (80) находится сплеш-скрин с выбором кодировки, перенаправляющий в зависимости от кодировки на различные порты того же самого хоста. [1]
Эта технология в настоящее время практически не применяется для веб-сайтов в связи с развитием поддержки кодировок в браузерах. У многих
Ссылки
Список портов TCP и UDP
Примечания
- ↑ Использование разных портов для разных кодировок
- 1 Номера портов
Wikimedia Foundation.
2010.
Полезное
Смотреть что такое «Порт (TCP/UDP)» в других словарях:
-
Порт (TCP/IP) — У этого термина существуют и другие значения, см. Порт (значения). В протоколах TCP и UDP (семейства TCP/IP) порт идентифицируемый номером системный ресурс, выделяемый приложению, выполняемому на некотором сетевом хосте, для связи с… … Википедия
-
Зарезервированные порты TCP/UDP — Для системных и некоторых популярных программ выделены общепринятые порты с номерами от 0 до 1023, называемые привилегированными или зарезервированными. Порты с номерами 1024 49151 называются зарегистрированными портами. Порты с номерами 1024… … Википедия
-
UDP — Название: User Datagram Protocol Уровень (по модели OSI): Транспортный Семейство: TCP/IP (иногда называют UDP/IP) Порт/ID: 17 (в IP) Спецификация: RFC 768 / STD 6 Основ … Википедия
-
TCP/IP — Стек протоколов TCP/IP (англ. Transmission Control Protocol/Internet Protocol) набор сетевых протоколов разных уровней модели сетевого взаимодействия DOD, используемых в сетях. Протоколы работают друг с другом в стеке (англ. stack, стопка)… … Википедия
-
TCP — Название: Transport Control Protocol Уровень (по модели OSI): Транспортный Семейство: TCP/IP Порт/ID: 6/IP Спецификация: RFC 793 / STD 7 Основные реализации … Википедия
-
UDP-пакет — UDP Название: User Datagram Protocol Уровень (по модели OSI): Транспортный Семейство: TCP/IP (иногда называют UDP/IP) Порт/ID: 17 (в IP) Спецификация: RFC 768 / STD 6 Основные реализации (клиенты): Ядро Windows, Linux, UNIX … Википедия
-
Udp — Название: User Datagram Protocol Уровень (по модели OSI): Транспортный Семейство: TCP/IP (иногда называют UDP/IP) Порт/ID: 17 (в IP) Спецификация: RFC 768 / STD 6 Основные реализации (клиенты): Ядро Windows, Linux, UNIX … Википедия
-
Tcp — Название: Transmission Control Protocol Уровень (по модели OSI): Транспортный Семейство: TCP/IP Порт/ID: 6/IP Спецификация: RFC 793 / STD 7 Основные реализации: Linux, Windows Расширяемость … Википедия
-
Порт (значения) — Порт: В Викисловаре есть статья «порт» Порт (лат. portus «гавань», «пристань») … Википедия
-
TCP-порт — Сетевой порт параметр протоколов UDP, определяющий назначение пакетов данных в формате Это условное число от 0 до 65535, позволяющие различным программам, выполняемым на одном хосте, получать данные независимо друг от друга (предоставляют так… … Википедия

Порт (port) — натуральное число, записываемое в заголовках протоколов транспортного уровня модели OSI (TCP, UDP, SCTP, DCCP).
Номера портов разделены на три диапазона: стандартные, зарегистрированные и динамические или частные:
Подробнее Справочник портов TCP, UDP, типы ICMP — с 0 по 1023
В стеке TCP/IP определены 4 уровня.
Для протокола TCP порт с номером 0 зарезервирован и не может использоваться. Для протокола UDP указание порта процесса-отправителя («обратного» порта) не является обязательным, и порт с номером 0 означает отсутствие порта. Таким образом, номер порта — число в диапазоне от 1 до 216-1=65 535.
Чтобы установить соединение между двумя процессами на разных компьютерах сети, необходимо знать не только интернет-адреса компьютеров, но и номера тех ТСР-портов (sockets), которые процессы используют на этих компьютерах. Любое TCP-соединение в сети Интернет однозначно идентифицируется двумя IP-адресами и двумя номерами ТСР-портов.
Протокол TCP умеет работать с поврежденными, потерянными, дублированными или поступившими с нарушением порядка следования пакетами. Это достигается благодаря механизму присвоения каждому передаваемому пакету порядкового номера и механизму проверки получения пакетов.
Когда протокол TCP передает сегмент данных, копия этих данных помещается в очередь повтора передачи и запускается таймер ожидания подтверждения.
Активные TCP соединения с интернетом (w/o servers)
# netstat -nt Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 192.26.95.251:56981 10.161.85.55:22 ESTABLISHED tcp 0 0 10.26.95.251:44596 10.26.95.226:2193 ESTABLISHED
Для сокетов TCP допустимы следующие значения состояния:
TCP RST – это сегмент TCP (обратите внимание, что TCP посылает сообщения сегментами, а НЕ пакетами, что часто неправильно употребляется в среде сетевых администраторов), который показывает, что с соединением что-то не так. RST посылается в следующих случаях: