На практике классы эквивалентности практически обязательны при тестировании всевозможных форм и полей ввода. Но Если заглянуть немного в глубь реализации функционала то эта техника может стать полезной не только для тестирования форм и полей ввода.
Приведем еще один пример (не такой классический как предыдущий, но не менее полезный):
У нас есть система работы с файлами. В системе возможны четыре типа файлов А, В, С, D. Каждый файл может находиться в одном из пяти состояний: Created, Edited, Loaded, Saved, Deleted.
Файл типа А может быть удален только в состоянии Created;
Файл типа В может быть удален только в состоянии Edited;
Файл типа C может быть удален только в состоянии Loaded;
Ну а файл типа D можно удалить только в состоянии Saved.
Это громоздкое условие можно неплохо иллюстрирует следующая таблица:
В данном примере важно помнить что подобное применение классов эквивалентности возможно только в случае если есть полная уверенность в том что за обработку удалений отвечает один и тот же код. В любом случае возможность познать систему чуть глубже окажет позитивный эффект на тестирование.
Если же у вас достаточно времени на проведение 20ти тестов, то следует провести эти 20 тестов и спать спокойно. Жаль что времени почти всегда не хватает.
Граничные значения
В отличии от классов эквивалентности техника тест дизайна гордо именуемая Граничные значения произошла не из наблюдения за однотипным поведением тестируемых систем, а из часто наблюдаемых багов в определенных ситуациях. Довольно часто именно на границах диапазонов допустимых значений появляются довольно неприятные баги. Причин у этого может быть много но нас как тестировщиков не интересует что вызывает эти баги, нерадивость программиста или баг в фреймворке который он использует или возможно наш знак зодиака, нам важно знать в каких условиях возник баг.
Граничные значения являются идейным продолжением классов эквивалентности так как именно на границах этих классов проявляются, так интересующие нас, граничные значения.
Граничными значениями как видно являются 1 и 1000. Поскольку эта техника подразумевает проверку не только граничного значения но и двух соседних то к нашему набору тестов прибавятся еще 6 проверок (0, 1, 2, 999, 1000, 1001).
Сами диапазон допустимых значений и особенно их границы за частую не так тривиальны как в нашем примере, но если вы можете их выделить и скомбинировать с классами эквивалентности то вы получите хорошее (качественное) покрытие тестами вашей функциональности.
Эпилог
Классы эквивалентности и граничные значения одни из базовых техник тест дизайна, но несмотря на кажущуюся простоту и примитивность этих техник они очень полезны и могут в несколько раз сократить время необходимое на один тест раунд. А как показывает практика именно этот ресурс самый ценный в нашей жизни и работе и что особенно не честно невосполнимый.
Источник
говориМ о тестировании
простым языком


Тест-дизайн. Классы эквивалентности и граничные значения
В этой статье мы разберем одну из самых известных и фундаментальных техник, технику выделения классов эквивалентности и граничных значений.
В чем суть техники?
Основная задача определения классов эквивалентности и граничных значений — «уйти» от дублирующих проверок. Таким образом, мы сократим количество однотипных тестов до необходимого минимума. Как это можно представить?
Предположим, у нас много-много разных булок, сделаны они по одному рецепту, а вот форма у них немного разная. А теперь представьте, что вам необходимо определить вкус каждой булки. Что вы будете делать? Попробуете все или возьмете только одну, потому что остальные сделаны аналогично? Я думаю второй вариант будет более оптимальным)
В тестировании ситуация аналогичная. Только вместо булок наши тесты. И все немного сложнее.
Классы эквивалентности
Сначала дадим определение классам эквивалентности.
Эквивалентная область (equivalence partition) —часть области входных или выходных данных, для которой поведение компонента или системы, основываясь на спецификации, считается одинаковым.
Скорей всего было не очень понятно…

Проще говоря, любой тест, выполненный из одного и того же класса эквивалентности, приведет к точно такому же результату, как и выполнение всех остальные тестов из этого же класса.
Например, у нас есть 10 тестов из одного класса. Если один из этих тестов проходит корректно, и то все остальные пройдут корректно. И наоборот, если один из тестов приведет к падению системы, то и все остальные тесты, также приведут к падению.
Пока все еще абстрактно, давайте конкретизируем. Предположим, у нас планируется акция «Скидка 10% на покупку от 5 товаров». Нам необходимо проверить функционал скидки в зависимости от количества товаров. Что будем делать? Есть два варианта проверки:

Тестов получается очень много.
2. Попробовать выделить классы эквивалентности и оптимизировать проверки.
Пойдем по второму варианту, он более эффективный. У нас всего два разных результата выполнения теста – со скидкой и без скидки. Логично предположить, что класса эквивалентности тоже будет два. В одном тесты будут проверять наличие скидки в 10%, в другом ее отсутствие.
Графически это можно представить следующим образом:

Т.е. какой бы мы тест не взяли из первого класса, мы получим скидку в 0%, аналогично для второго класса эквивалентности.
Теперь теория и здравый смысл подсказывают нам, что можно взять не все тесты, а только несколько из каждого класса эквивалентности. Этого должно быть достаточно, чтобы проверить оба случая со скидкой.
Но теперь вопрос, какие тесты брать? Есть ли разница между ними, может быть все-таки есть небольшие отличия?
Граничные значения
Путем долгого времени наблюдения за разработкой и анализа багов, специалисты пришли к выводу, что большинство ошибок возникает именно на границах между классами эквивалентности. Т.е. нам в первую очередь важно проверить переходы на стыке границ каждого класса, так как именно там велик риск возникновения ошибок.
Поэтому для эффективного тестирования нам необходимо выделить у каждого класса граничные значения. Давайте попробуем сделать на нашем примере:

Итого, 4 теста вместо 100 с учетом сохранения тестового покрытия.
Наша задача, как тестировщика, уметь правильно определить и работать с классами эквивалентности и граничными значениями. Выше мы рассмотрели пример с позиции черного ящика. У него есть существенные минус, мы не знаем как реализована работа функционала с точки зрения кода. Следовательно, не можем со 100% уверенностью правильно выделить классы эквивалентности.
Давайте рассмотрим пример посложней. Нам необходимо проверить корректность бокового меню на сайте из 10 страниц. Вот такое:
Страницы сами по себе одинаковые и отличаются только содержанием, боковое меню зрительно полностью идентично.
Только что пройденный материал подсказывает нам, что есть один класс эквивалентности и он включает в себя все 10 страниц. Но на практике есть как минимум два варианта:
1. Если сайт сделан на HTML, в том числе и боковое меню, то необходимо проверять КАЖДУЮ страницу, так как на каждой странице боковое меню работает отдельно от остальных.
2. Если сайт сделан с помощью, например, шаблонизаторов, то тогда выделить 10 страниц в класс эквивалентности можно, так как код меню хранится отдельно.
Т.е. в зависимости от реализации, классы будут разные. Как это определить? Если вы знаете языки программирования и у вас есть доступ в репозиторий, то посмотреть в код. Если вы не поняли, что я сейчас написал, то подойдет и второй вариант) Поговорите с программистом, который делал эту функциональность и уточните у него, правильно ли вы делаете.
Источник
Тестовые примеры. Классы эквивалентности. Ручное тестирование в MVSTE
5.2.2 Классы эквивалентности
Рассмотрим другой пример.
Функция, которую будем тестировать:
После исправлений функциональное требование 4.2.1.1. будет выглядеть так:
Тестирование на допустимые данные ничем не будет отличаться от тестирования функции деления. Составим классы эквивалентности.
Учитывая то, что у нас два идентичных входных параметра, для полного рассмотрения всех классов эквивалентности необходимо составить и проверить 7*7=49 тестовых примеров, что все равно гораздо меньше, чем полный перебор.
При этом, как показал тест с делением, ошибка может проявиться лишь в нескольких из этих примеров, которые не сильно отличаются от остальных граничных классов эквивалентности.
Некоторые классы эквивалентности не удовлетворяют требованию 4.2.1.1. так как выводят сумму за допустимые пределы. Поведение метода на таких входных данных описано в требовании 4.2.1.2.
На рис.5.2 показано возможное выделение классов эквивалентности (цветами изображены области корректных и некорректных значений, а кружками — сами классы эквивалентности):

Иногда удобнее составить классы эквивалентности по выходному параметру (в данном случае их будет 7) и уже по ним подбирать входные данные и составлять тестовые примеры.
Основной способ поиска дефектов – передача системе данных, не предусмотренных требованиями: слишком длинных или слишком коротких строк, неверных символов, чисел за пределами вычислимого диапазона и т.п. Неверные данные, как и допустимые, также можно разделять на различные классы эквивалентности. В качестве простого примера снова рассмотрим функцию сложения.
Замечание. Как уже отмечалось выше, тест-требования составлены очень подробно и, фактически, соответствуют тестовым примерам. Поэтому поведение метода на некорректных данных описано в спецификации, хотя подобная ситуация в жизни редко встречается.
На самом деле, взглянув на любую из рассмотренных функций, в общем случае выделяют 4 основных класса эквивалентности (рис.5.3).

Это тот минимум, на котором и надо протестировать метод. Однако интуиция и опыт тестировщика подсказывают, что эти классы можно разбить на более мелкие подклассы, в которых часто возникают ошибки. Так, первый класс для функции нахождения частного мы разбили на 14 подклассов, в результате чего и обнаружили ошибку.
Помимо рассмотренных классов тестовых примеров, направленных на выявление различных дефектов в работе программной системы, выделяют также тестовые примеры реинициализации системы, повторного ввода данных, устойчивости системы и другие.
Источник
Накидать классы эквивалентности кэ на поле ввода номера дома








Что пишут в блогах
В этом видео я показал как можно визуализировать покрытие автоматическими тестами для GraphQL api с помощью инструмента Reqover.
Cегодня хочу поговорить с вами на тему комьюнити для тестировщиков.
Как и в любой сфере, среди тестировщиков существует куча различных комьюнити. Раньше они организовывались в скайпе.
Забываю похвастаться статусом книги.

Онлайн-тренинги
Конференции
Heisenbug 2021 Moscow
Большая техническая конференция для тестировщиков
5-7 октября 2021, онлайн
Что пишут в блогах (EN)
Разделы портала
Про инструменты
Ещё в самом начале предыдущего онлайн-тренинга «Практикум по тест-дизайну» я обещал ученикам написать о том, как выполнять разбиение входных данных на подобласти (классы эквивалетности) в ситуациях, когда в поле ввода можно указать произвольную строку, а по смыслу туда должно быть введено число. Увы, им пришлось выполнять домашние задания без моих подсказок (впрочем, может быть это совсем не плохо). Но я всё таки решил перед тем, как начнутся занятия следующей группы, написать небольшую “шпаргалку”.
Подавляющее большинство книг и статей, где описывается эта техника, в качестве примера рассматривают разбиение на классы множества чисел. При этом совершенно не учитывается тот факт, что в реальных приложениях с пользовательским интерфейсом все поля ввода строковые, и даже если есть ограничения на вводимые символы – это тоже предмет тестирования.
А что рекомендуется делать с “нечислами”? Они все объединяются в один большой класс “невалидных” данных, из него наугад берётся одно-два значения и всё.
Представление о том, что из себя представляет “число” сильно зависит от конкретной реализации, и я покажу вам распространённые примеры строк, которые с точки зрения программы являются числом, хотя не всякий об этом догадается. А также опишу общую схему рассуждений, позволяющую выполнить разбиение на классы эквивалетности для строковых полей ввода, предназначенных для ввода числовых значений.
Итак, давайте представим себе, что у нас есть приложение, которое на вход принимает строку, но по смыслу она должна интерпретироваться как число. Например, вот такое: Онлайн-калькулятор для перевода единиц времени.

Все возможные строки, разумеется, можно разделить на два больших класса – “числа” и “нечисла”. Но я дам этим классам другие, более длинные, но при этом более точные названия:
В такой формулировке сразу становится ясно, что программа на вход получает строку, которая перво-наперво по каким-то правилам преобразуется в число. Если это преобразование прошло успешно – полученное число используется в вычислениях, результат которых мы можем наблюдать. А если преобразовать строку в число не удалось – мы получаем информацию об этом либо в виде сообщения о возникшей проблеме, либо в виде “бессмысленного” результата вычислений.
Мы можем без труда определить, как именно наш преобразователь времени ведёт себя в той и в другой ситуации, для этого достаточно подать на вход какое-нибудь значение, которое вне всяких сомнений должно интерпретироваться как число (например, “1”):

а также какое-нибудь значение, которое абсолютно точно числом не является (например, “привет”):

То есть здесь мы как раз имеем случай, когда “невалидное” входное значение приводить к бессмысленному результату (NaN означает “Not a Number”).
Теперь давайте попробуем определить, какие же строки программа будет интерпретировать как числа, то есть начнём выделять в наших больших классах подклассы меньшего размера, но зато описанные конструктивно. Начнём с простого:
1.1. строка, представляющая собой последовательность цифр, интерпретируется как целое число.
Очевидно? Вполне. Хотя нет, не совсем очевидно. Наверняка вы уже готовы были поймать меня за руку – какой длины последовательность цифр интерпретируется как число? Всё верно, правильный вопрос.
Чтобы ответить на него, нужно опять применить технику разбиения на подобласти. Впрочем, здесь мы как раз имеем достаточно простой случай – длина последовательности это целое неотрицательное число, так что техника работает в полном соответствии с учебниками.
Минимальная длина последовательности – ноль. Максимальная длина – “сколько влезет”.
А сколько влезет? И куда влезет? В обсуждаемом приложении не указано никаких ограничений на размер поля ввода. Может быть браузер накладывает какое-нибудь ограничение, но лично мне про это ничего не известно, и даже если оно есть – наверняка в разных браузерах оно разное. Если введённые данные передаются на сервер в виде GET-запроса, возможно, имеется ограничение на длину запроса – согласно стандарту RFC 2068 они должны поддерживать не менее 255 байтов, но конечно же все реально способны обрабатывать запросы большей длины, и конечно же это опять зависит от браузера и от веб-сервера.
Конвертер, который мы используем в качестве примера, реализован на языке JavaScript, на сервер никаких данных не отправляется, все вычисления производятся внутри браузера. Установленный на моём ноутбуке Google Chrome успешно справился со строкой, состоящей из 10 000 000 девяток, а вот строку из 100 000 000 девяток он обработать уже не смог – после длительного раздумья он вывел сообщение “Опаньки…” и предложил перегрузить страницу, потому что на ней возникла ошибка. Следовательно, где-то между этими значениями и находится та самая максимальная длина, определяемая по принципу “сколько влезет”. Поэтому уточняем:
1.1. строка, представляющая собой последовательность цифр, интерпретируется как целое число, если длина строки не превышает некоторое Максимальное Значение.
Впрочем, куда раньше, на существенно более коротких последовательностях, начинает наблюдаться вот такая картина (скриншот показывает ситуацию, когда введена последовательность из 1000 девяток):

При вычислениях возникло переполнение, однако Infinity – это не NaN, то есть согласно описанном выше уговору мы будем считать, что такая последовательность (а также и более длинные последовательности цифр) всё таки может считаться числом.
А что там с другой стороны? Последовательность нулевой длины – это пустая строка. Число ли это? Чуства и логика подсказывают, что нет, однако приложение не согласно с ними и интерпретирует пустую строку как число ноль:

На всякий случай ещё проверим последовательности длины 1, как ближайшей к минимальной граничной.
Только чур не пытайтесь найти такую длину, при которой ещё не происходит переполнения, потому что это уже к длине не имеет никакого отношения, здесь важна уже не длина последовательности цифр, а само значение числа. Это оставим читателю в качестве упражнения (подсказка: JavaScript реализует стандарт IEEE-754 и может работать с числами двойной точности), а сами вернёмся к рассмотрению разных других строк.
С последовательностями цифр мы разобрались. Давайте попробуем добавить какие-нибудь “нецифры”. Перестанет ли строка быть числом?
Наверняка вы сами без труда вспомните некоторые случаи, когда этого (может быть) не случится – пробелы в начале и в конце, а также ведущие нули. Действительно, они обрезаются, а оставщаяся строка интерпретируется как число. Итак:
1.2 строка, интерпретируемая как число, также интерпретируется как число, если добавить в начале некоторое количество нулей, при этом ведущие нули игнорируются,
1.3. строка, интерпретируемая как число, также интерпретируется как число, если добавить в начале или в конце некоторое количество пробелов, при этом все пробелы игнорируются.

Ладно, двигаемся дальше – вспоминаем про отрицательные числа:
1.4. строка, интерпретируемая как число, также интерпретируется как число, если добавить в начало знак минус или плюс.
Надеюсь про плюс никто не забыл, да? Кстати, между минусом/плюсом и первой цифрой могут быть пробелы. Ну и перед ними тоже, конечно.
Гм… Кажется, у нас проблема. Помните ещё про пустую строку? Мы же согласились считать её как бы числом. Зря согласились – если “перед ней” поставить минус или плюс, числа не получается.
Ладно, выкидываем пустую строку, будем рассматривать её отдельно, как особый случай, а минимальную длину последовательности цифр объявим равной единице.
Кстати, вас не насторожил тот факт, что я перестал говорить “целое число”? В правиле выделения подобласти 1.1 я его написал, а в следующих правилах нет.
Всё верно, эти правила работают также и для нецелых чисел. Добавляем новое правило:
1.5. строка, состоящая из двух неразрывных цепочек цифр, разделённых десятичной точкой, интерпретируется как число
Углубляться в подробности, связанные с точностью вычислений не станем, отметим лишь, что здесь тоже можно применить технику разбиения на подобласти. К чему применить? К количеству значащих цифр, или к количеству знаков после запятой, в зависимости от того, как интерпретируется понятие точности в конкретном приложении. Но при этом следует отметить, что для чисел с плавающей точкой техника разбиения на подобласти работает плохо, за подробностями я отправляю вас к статьям Виктора Кулямина про тестирование математических функций (нетерпеливые могут сразу заглянуть в конец раздела 4.3, а любопытные могут поискать ещё другие статьи и презентации на ту же тему на личной страничке Виктора).
А всё почему? Потому что JavaScript реализует стандарт IEEE-754.
Вообще-то к этому моменту вы, наверное, догадались, что я неспроста уже второй раз упомянул этот стандарт. Да, вы правы. Пришло время перейти к более сложным строкам, которые ну совсем не последовательности цифр, но при этом всё равно интерпретируются как числа. Давайте введём в наше приложение, например, число 120:

Оно работает! Думаете, это только этот конвертер такой, что я специально его выбрал? Ничего подобного! Откройте с десяток наугад выбранных веб-магазинов или онлайн-калькуляторов – добрая половина согласится принять числа в таком формате. А теперь сходите и проверьте своё собственное приложение.
Хотя нет, подождите. Это ещё не всё.
Во-первых, надо добавить ещё одно правило:
1.6. строка, состоящая из числа, за которым следует символ ‘e’, за которым следует целое число, интерпретируется как число
Да, 100e-1 = 10, а плюс можно не указывать, так что 1.0e2 = 1.0e+2 = 100.
А во-вторых, есть ещё и другие строки, которые тоже интерпретируются как числа, вот пример:

Все числа до этого момента у нас были в десятеричном представлении, а теперь появились шестнадцатеричные. Я намеренно в самом начале, когда ещё первый раз сформулировал правило 1.1 не стал акцентировать внимание на том, что такое “цифра”.
Что же, добавляем новое правило:
1.7. строка, состоящая из символов ‘0x’, за которыми следует неразрывная последовательность шестнадцатеричных цифр, интерпретируется как шестнадцатеричное целое число
Правило 1.1 при этом придётся тоже уточнить, указав, что там могут участвовать только десятеричные цифры. Приятной новостью является то, что шестнадцатеричные числа могут быть только целые (ну, то есть, в этом приложении так, может быть где-то и дробные бывают). Так что максимум, что можно ещё сделать с ними – добавить плюс/минус, да пробелы в начале и в конце.
Ну вот, теперь можете проверять своё приложение, сразу и на числа с плавающей точкой, и на шестнадцатеричные числа. А я тем временем расскажу ещё кое-что про строки, которые могут быть числами.
Однажды мне встретился интернет-магазин, который принимал не только числа в шестнадцатеричном представлении, но и в восьмеричном. То есть ноль в начале не игнорировался, как это бывает обычно, а свидетельствовал о том, что число следует интерпретировать как восьмеричное. Так что правило 1.2 тоже не надо вешать на стенку, и оно не всегда справедливо.
Попробуйте в наш подопытный конвертер ввести строку Infinity – вы удивитесь, но это тоже число (а в некоторых языках программирования распознаётся также строка Inf):

В качестве записной книжки для ведения списка дел я использую замечательный сервис Toodledo. Так вот, там при создании записи можно в поле ввода даты написать, например, “tomorrow” или “next Monday” – и оно работает! Для таких преобразований бывают даже специальные библиотеки, например, в языке Perl для анализа дат используется Date::Manip, а для анализа чисел Lingua::EN::Words2Num. Мне лично не приходилось тестировать приложения, где можно было бы вводить числа в текстовом виде, но такое действительно иногда встречается на практике.
Ещё одно любопытное “число”, специально для тех, кто знаком с языком программирования Perl – “0 but true”.
А вот пример приложения – калькулятор доходности вкладов, в котором число в шестнадцатеричном представлении проходит валидацию, которая выполняется средствами JavaScript, но вызывает проблемы при вычислениях на серверной стороне. Попробуйте указать сумму вклада в шестнадцатеричном виде, например, 0xff – и вы увидите, что серая табличка с расчётами не появится на странице. Добиться аналогичного эффекта, вводя положительные десятеричные числа, мне не удалось.
(Примечание: так работал калькулятор во время написания статьи, сейчас реализация уже изменилась)
Этот приём позволяет иногда “протолкнуть” через валидатор неправильное значение, которое может привести к сбоям на серверной стороне.
В общем, надеюсь, вы поняли, что “строка, которая может быть проинтерпретирована как число” – это не такая простая штука, как может показаться на первый взгляд.
А что же попадает во второй большой класс, “нечисла”. Туда попадает всё остальное.
Да, вот такое неконструктивное определение. И при этом я обещал в самом начале статьи рассказать вам общую схему рассуждений, позволяющую выполнить разбиение на классы эквивалетности. Пожалуйста, вот эта схема, в одном абзаце:
Сначала считаем, что все строки находятся в классе “нечисел”. Как только вы прочитали в требованиях, или в документации, или узнали от коллег, или прочитали в какой-нибудь статье (например, в этой) о том, что строки определённого вида могут интерпретироваться как число – вы выделяете соответствующее подмножество строк и проверяете. Если оказалось, что ваше приложение не считает строки такого вида числами, вы сбрасываете всё обратно в большой класс “нечисел”. Ну а если приложение всё-таки согласилось считать эти строки числами, тогда они выделяются в отдельный подкласс и переводятся в класс “чисел”.
Вот и всё, очень простой алгоритм 🙂
Ну так что, принимает ваше приложение шестнадцатеричные числа или нет, а?
Источник
Вам также может понравиться
Adblock
detector
Определим алгоритм использования техники классов эквивалентности:
1. Определить классы эквивалентности.
2. Выбрать по одному тесту для каждого класса, выписать все тесты для всех классов.
3. Выполнить тесты.
Пример использования классов эквивалентности по алгоритму
на примере формы обратной связи сайта radar4site.ru:
На странице «Обратная связь» есть всего два элемента: поле для ввода сообщения и кнопка «Отправить».
1. Определим классы эквивалентности для поля ввода сообщения:
Попробуем выделить классы эквивалентности по двум направлениям:
- По количеству символов.
- По типу символов (буквы, цифры, специальные символы).
1.1. По количеству символов:
1.1.1. Начнём вводить текст в поле ввода до тех пор, пока не появится ограничение на длину. В нашем случае интерфейс подсказал нам, что больше 1000 символов ввести не сможем в это поле. На всякий случай определим количество символов при помощи инструмента Количество символов.
1.1.2. Таким образом, найдено ограничение для длину поля — 1000 символов, т.е. это верхняя граница.
1.1.3. Какой будет нижняя граница? Меньше нуля ввести не сможем. А можно ли ввести 0 символов? Можно оставить поле пустым и нажать «Отправить», в таком случае считаем, что 0 символов допустимы. Поэтому нижняя граница — 0 символов.
1.1.4. Таким образом, определен класс эквивалентности «по количеству символов» с допустимой нижней границей 0 символов и допустимой верхней границей 1000 символов.
1.2. По типу символов:
1.2.1. Поскольку это поле для ввода сообщения, мы можем вводить любые символы, поэтому можно в одном классе проверять сразу множество символов разного типа (буквы, цифры, спец. символы).
1.2.2. Таким образом, определен класс эквивалентности «по типу символов».
2. Выбираем по одному тесту в каждом классе эквивалентности:
2.1. По количеству символов: любой текст длиной в 101 символов, например «Здравствуйте. Ваш сайт помог мне чуть лучше понять, чем занимаются тестировщики. Спасибо Вам большое!».
2.2. По типу символов: текст, содержащий символы разного типа, например: «йцукенгшщзхъфывапролджэячсмитьбю.,1234567890-=ё!»№;%:?*()_+@#$^&|/}{[]><«.
3. Выполним тесты (введя наши значения в поле ввода и нажав на кнопку «Отправить»). В нашем случае уже проверил — значения обработались успешно, ошибок нет, сообщение отправилось.
Теперь представим, сколько мы сэкономили времени. Для первого класса эквивалентности у нас вместо тысячи тестов всего один. Для второго класса эквивалентности мы сразу определили класс допустимых значений и не пришлось генерировать множество тестов, вместо этого у нас получится всего один тест.
Как ещё можно докрутить технику? Мы можем определить ещё несколько классов эквивалентности, например, проверить символы английского алфавита (других алфавитов), проверить другие специальные символы, проверить эмодзи, смайлики и т.д.
Похожие заметки:
Классы эквивалентности определение
Классы эквивалентности в тестировании
Автор: Алексей Баранцев
Ещё в самом начале предыдущего онлайн-тренинга «Практикум по тест-дизайну» я обещал ученикам написать о том, как выполнять разбиение входных данных на подобласти (классы эквивалетности) в ситуациях, когда в поле ввода можно указать произвольную строку, а по смыслу туда должно быть введено число. Увы, им пришлось выполнять домашние задания без моих подсказок (впрочем, может быть это совсем не плохо). Но я всё таки решил перед тем, как начнутся занятия следующей группы, написать небольшую “шпаргалку”.
Подавляющее большинство книг и статей, где описывается эта техника, в качестве примера рассматривают разбиение на классы множества чисел. При этом совершенно не учитывается тот факт, что в реальных приложениях с пользовательским интерфейсом все поля ввода строковые, и даже если есть ограничения на вводимые символы – это тоже предмет тестирования.
А что рекомендуется делать с “нечислами”? Они все объединяются в один большой класс “невалидных” данных, из него наугад берётся одно-два значения и всё.
И всё? А вот и нет!
Представление о том, что из себя представляет “число” сильно зависит от конкретной реализации, и я покажу вам распространённые примеры строк, которые с точки зрения программы являются числом, хотя не всякий об этом догадается. А также опишу общую схему рассуждений, позволяющую выполнить разбиение на классы эквивалетности для строковых полей ввода, предназначенных для ввода числовых значений.
Итак, давайте представим себе, что у нас есть приложение, которое на вход принимает строку, но по смыслу она должна интерпретироваться как число. Например, вот такое: Онлайн-калькулятор для перевода единиц времени.
Все возможные строки, разумеется, можно разделить на два больших класса – “числа” и “нечисла”. Но я дам этим классам другие, более длинные, но при этом более точные названия:
- множество строк, которые программа интерпретирует как числа;
- множество строк, которые программа не может интерпретировать как числа.
В такой формулировке сразу становится ясно, что программа на вход получает строку, которая перво-наперво по каким-то правилам преобразуется в число. Если это преобразование прошло успешно – полученное число используется в вычислениях, результат которых мы можем наблюдать. А если преобразовать строку в число не удалось – мы получаем информацию об этом либо в виде сообщения о возникшей проблеме, либо в виде “бессмысленного” результата вычислений.
Мы можем без труда определить, как именно наш преобразователь времени ведёт себя в той и в другой ситуации, для этого достаточно подать на вход какое-нибудь значение, которое вне всяких сомнений должно интерпретироваться как число (например, “1”):
а также какое-нибудь значение, которое абсолютно точно числом не является (например, “привет”):
То есть здесь мы как раз имеем случай, когда “невалидное” входное значение приводить к бессмысленному результату (NaN означает “Not a Number”).
Теперь давайте попробуем определить, какие же строки программа будет интерпретировать как числа, то есть начнём выделять в наших больших классах подклассы меньшего размера, но зато описанные конструктивно. Начнём с простого:
1.1. строка, представляющая собой последовательность цифр, интерпретируется как целое число.
Очевидно? Вполне. Хотя нет, не совсем очевидно. Наверняка вы уже готовы были поймать меня за руку – какой длины последовательность цифр интерпретируется как число? Всё верно, правильный вопрос.
Чтобы ответить на него, нужно опять применить технику разбиения на подобласти. Впрочем, здесь мы как раз имеем достаточно простой случай – длина последовательности это целое неотрицательное число, так что техника работает в полном соответствии с учебниками.
Минимальная длина последовательности – ноль. Максимальная длина – “сколько влезет”.
А сколько влезет? И куда влезет? В обсуждаемом приложении не указано никаких ограничений на размер поля ввода. Может быть браузер накладывает какое-нибудь ограничение, но лично мне про это ничего не известно, и даже если оно есть – наверняка в разных браузерах оно разное. Если введённые данные передаются на сервер в виде GET-запроса, возможно, имеется ограничение на длину запроса – согласно стандарту RFC 2068 они должны поддерживать не менее 255 байтов, но конечно же все реально способны обрабатывать запросы большей длины, и конечно же это опять зависит от браузера и от веб-сервера.
Конвертер, который мы используем в качестве примера, реализован на языке JavaScript, на сервер никаких данных не отправляется, все вычисления производятся внутри браузера. Установленный на моём ноутбуке Google Chrome успешно справился со строкой, состоящей из 10 000 000 девяток, а вот строку из 100 000 000 девяток он обработать уже не смог – после длительного раздумья он вывел сообщение “Опаньки…” и предложил перегрузить страницу, потому что на ней возникла ошибка. Следовательно, где-то между этими значениями и находится та самая максимальная длина, определяемая по принципу “сколько влезет”. Поэтому уточняем:
1.1. строка, представляющая собой последовательность цифр, интерпретируется как целое число, если длина строки не превышает некоторое Максимальное Значение.
Впрочем, куда раньше, на существенно более коротких последовательностях, начинает наблюдаться вот такая картина (скриншот показывает ситуацию, когда введена последовательность из 1000 девяток):
При вычислениях возникло переполнение, однако Infinity – это не NaN, то есть согласно описанном выше уговору мы будем считать, что такая последовательность (а также и более длинные последовательности цифр) всё таки может считаться числом.
А что там с другой стороны? Последовательность нулевой длины – это пустая строка. Число ли это? Чуства и логика подсказывают, что нет, однако приложение не согласно с ними и интерпретирует пустую строку как число ноль:
На всякий случай ещё проверим последовательности длины 1, как ближайшей к минимальной граничной.
Только чур не пытайтесь найти такую длину, при которой ещё не происходит переполнения, потому что это уже к длине не имеет никакого отношения, здесь важна уже не длина последовательности цифр, а само значение числа. Это оставим читателю в качестве упражнения (подсказка: JavaScript реализует стандарт IEEE-754 и может работать с числами двойной точности), а сами вернёмся к рассмотрению разных других строк.
С последовательностями цифр мы разобрались. Давайте попробуем добавить какие-нибудь “нецифры”. Перестанет ли строка быть числом?
Наверняка вы сами без труда вспомните некоторые случаи, когда этого (может быть) не случится – пробелы в начале и в конце, а также ведущие нули. Действительно, они обрезаются, а оставщаяся строка интерпретируется как число. Итак:
1.2 строка, интерпретируемая как число, также интерпретируется как число, если добавить в начале некоторое количество нулей, при этом ведущие нули игнорируются,
1.3. строка, интерпретируемая как число, также интерпретируется как число, если добавить в начале или в конце некоторое количество пробелов, при этом все пробелы игнорируются.
Всё верно? Нет! Во-первых, не забывайте про Максимальное Значение длины, если добавить слишком много нулей или пробелов, строка перестанет быть числом, даже если эти пробелы добавлялись к совершенно безобидному небольшому числу. Во-вторых, добавлять пробелы и нули можно только в строго определённом порядке — пробелы с краю, нули ближе к «основной части» числа, в другом порядке они уже не будут игнорироваться:
Да, можно эти правила уточнить, ввести понятие “неразрывной последовательности цифр”, к которой уже можно прибавлять пробелы. Но если вы собрались сейчас записать эти правила и повесить на стенку – не делайте этого! Вот вам пример приложения которое действует в точности наоборот – там можно вставлять пробелы куда угодно, хоть в начало, хоть в конец, хоть в середину. А есть и такие (в основном десктопные), в которых пробелы никуда нельзя вставлять, например, так ведёт себя диалог задания размера рисунка в графическом редакторе Paint в Windows 7.
Ладно, двигаемся дальше – вспоминаем про отрицательные числа:
1.4. строка, интерпретируемая как число, также интерпретируется как число, если добавить в начало знак минус или плюс.
Надеюсь про плюс никто не забыл, да? Кстати, между минусом/плюсом и первой цифрой могут быть пробелы. Ну и перед ними тоже, конечно.
Гм… Кажется, у нас проблема. Помните ещё про пустую строку? Мы же согласились считать её как бы числом. Зря согласились – если “перед ней” поставить минус или плюс, числа не получается.
Ладно, выкидываем пустую строку, будем рассматривать её отдельно, как особый случай, а минимальную длину последовательности цифр объявим равной единице.
Кстати, вас не насторожил тот факт, что я перестал говорить “целое число”? В правиле выделения подобласти 1.1 я его написал, а в следующих правилах нет.
Всё верно, эти правила работают также и для нецелых чисел. Добавляем новое правило:
1.5. строка, состоящая из двух неразрывных цепочек цифр, разделённых десятичной точкой, интерпретируется как число
Углубляться в подробности, связанные с точностью вычислений не станем, отметим лишь, что здесь тоже можно применить технику разбиения на подобласти. К чему применить? К количеству значащих цифр, или к количеству знаков после запятой, в зависимости от того, как интерпретируется понятие точности в конкретном приложении. Но при этом следует отметить, что для чисел с плавающей точкой техника разбиения на подобласти работает плохо, за подробностями я отправляю вас к статьям Виктора Кулямина про тестирование математических функций (нетерпеливые могут сразу заглянуть в конец раздела 4.3, а любопытные могут поискать ещё другие статьи и презентации на ту же тему на личной страничке Виктора).
А всё почему? Потому что JavaScript реализует стандарт IEEE-754.
Вообще-то к этому моменту вы, наверное, догадались, что я неспроста уже второй раз упомянул этот стандарт. Да, вы правы. Пришло время перейти к более сложным строкам, которые ну совсем не последовательности цифр, но при этом всё равно интерпретируются как числа. Давайте введём в наше приложение, например, число 120:
Оно работает! Думаете, это только этот конвертер такой, что я специально его выбрал? Ничего подобного! Откройте с десяток наугад выбранных веб-магазинов или онлайн-калькуляторов – добрая половина согласится принять числа в таком формате. А теперь сходите и проверьте своё собственное приложение.
Хотя нет, подождите. Это ещё не всё.
Во-первых, надо добавить ещё одно правило:
1.6. строка, состоящая из числа, за которым следует символ ‘e’, за которым следует целое число, интерпретируется как число
Да, 100e-1 = 10, а плюс можно не указывать, так что 1.0e2 = 1.0e+2 = 100.
А во-вторых, есть ещё и другие строки, которые тоже интерпретируются как числа, вот пример:
Все числа до этого момента у нас были в десятеричном представлении, а теперь появились шестнадцатеричные. Я намеренно в самом начале, когда ещё первый раз сформулировал правило 1.1 не стал акцентировать внимание на том, что такое “цифра”.
Что же, добавляем новое правило:
1.7. строка, состоящая из символов ‘0x’, за которыми следует неразрывная последовательность шестнадцатеричных цифр, интерпретируется как шестнадцатеричное целое число
Правило 1.1 при этом придётся тоже уточнить, указав, что там могут участвовать только десятеричные цифры. Приятной новостью является то, что шестнадцатеричные числа могут быть только целые (ну, то есть, в этом приложении так, может быть где-то и дробные бывают). Так что максимум, что можно ещё сделать с ними – добавить плюс/минус, да пробелы в начале и в конце.
Ну вот, теперь можете проверять своё приложение, сразу и на числа с плавающей точкой, и на шестнадцатеричные числа. А я тем временем расскажу ещё кое-что про строки, которые могут быть числами.
Если ваше приложение написано на языке Pascal или Delphi, думаю, вам будет полезно знать, что в этом языке представляются в несколько ином виде – впереди стоит знак $ (доллар), а не 0x.
Однажды мне встретился интернет-магазин, который принимал не только числа в шестнадцатеричном представлении, но и в восьмеричном. То есть ноль в начале не игнорировался, как это бывает обычно, а свидетельствовал о том, что число следует интерпретировать как восьмеричное. Так что правило 1.2 тоже не надо вешать на стенку, и оно не всегда справедливо.
Попробуйте в наш подопытный конвертер ввести строку Infinity – вы удивитесь, но это тоже число (а в некоторых языках программирования распознаётся также строка Inf):
В качестве записной книжки для ведения списка дел я использую замечательный сервис Toodledo. Так вот, там при создании записи можно в поле ввода даты написать, например, “tomorrow” или “next Monday” – и оно работает! Для таких преобразований бывают даже специальные библиотеки, например, в языке Perl для анализа дат используется Date::Manip, а для анализа чисел Lingua::EN::Words2Num. Мне лично не приходилось тестировать приложения, где можно было бы вводить числа в текстовом виде, но такое действительно иногда встречается на практике.
Ещё одно любопытное “число”, специально для тех, кто знаком с языком программирования Perl – “0 but true”.
А вот пример приложения – калькулятор доходности вкладов, в котором число в шестнадцатеричном представлении проходит валидацию, которая выполняется средствами JavaScript, но вызывает проблемы при вычислениях на серверной стороне. Попробуйте указать сумму вклада в шестнадцатеричном виде, например, 0xff – и вы увидите, что серая табличка с расчётами не появится на странице. Добиться аналогичного эффекта, вводя положительные десятеричные числа, мне не удалось.
(Примечание: так работал калькулятор во время написания статьи, сейчас реализация уже изменилась)
Этот приём позволяет иногда “протолкнуть” через валидатор неправильное значение, которое может привести к сбоям на серверной стороне.
В общем, надеюсь, вы поняли, что “строка, которая может быть проинтерпретирована как число” – это не такая простая штука, как может показаться на первый взгляд.
А что же попадает во второй большой класс, “нечисла”. Туда попадает всё остальное.
Да, вот такое неконструктивное определение. И при этом я обещал в самом начале статьи рассказать вам общую схему рассуждений, позволяющую выполнить разбиение на классы эквивалетности. Пожалуйста, вот эта схема, в одном абзаце:
Сначала считаем, что все строки находятся в классе “нечисел”. Как только вы прочитали в требованиях, или в документации, или узнали от коллег, или прочитали в какой-нибудь статье (например, в этой) о том, что строки определённого вида могут интерпретироваться как число – вы выделяете соответствующее подмножество строк и проверяете. Если оказалось, что ваше приложение не считает строки такого вида числами, вы сбрасываете всё обратно в большой класс “нечисел”. Ну а если приложение всё-таки согласилось считать эти строки числами, тогда они выделяются в отдельный подкласс и переводятся в класс “чисел”.
Вот и всё, очень простой алгоритм 
Ну так что, принимает ваше приложение шестнадцатеричные числа или нет, а?
Обсудить в форуме
Рассмотрим теперь некоторые специальные
бинарные отношения, используя введённые
обозначения и представления, а также
дадим некоторые новые определения.
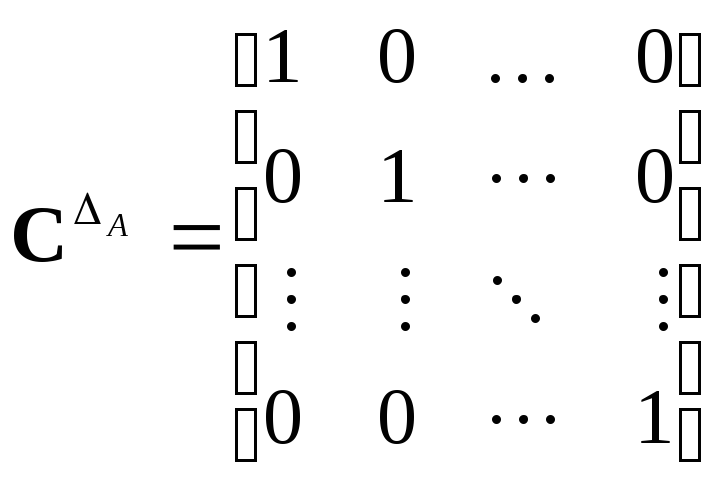
Назовём отношение A = {(x, x) | xA}диагональнымотношением множестваA. Это самый узкий
класс эквивалентностей, возможный в
некоторой системе обозначений. Обычно
это просто отношение равенства наА:A = {(x, y) | xA & yA & x=y}.
Графически ему соответствует набор
вершин с петлями без рёбер между
вершинами. Матрица такого отношения
будет диагональной (единичной) логической
матрицей. Отсюда название.
Рассматривавшееся свойство рефлексивности
может тогда быть выражено формулой
A .
Симметричность можно выразить формулой
-1 =.
Транзитивность можно выразить формулой
.
(можно написать и2)
Таким образом, получаем определение
для отношения эквивалентности
— эквивалентность на множестве A(A &-1 =&).
Если - некоторое
бинарное отношение (AA),
аx– некоторый элемент
(xA),
то для этого элемента можно указать
множества элементов, связанных с ним
потак, что он будет
являться первым элементом в упорядоченной
паре {y | (x, y)}.
Графически это можно представить как
все вершины, куда можно попасть изxза один шаг:

Аналогично можно указать и множество
{y | (y, x)},
вершин, где начинаются стрелки, идущие
вx.
Но если -1 =то {y | (x, y)}={y | (y, x)}.
Для симметричных отношений обозначим
такое множество как
[x] = {y | (x, y)}
= {y | (y, x)}
Если это эквивалентность, то будем называть
[x]классом эквивалентностиэлементаxпо отношению.
Это есть простомножество элементов,
эквивалентных x.
При этом элементxназываютобразующимкласса [x].
Для классов эквивалентности некоторого
AAследует отметить следующие свойства.
-
Каждый элемент принадлежит своему
классу эквивалентности.
xA x[x]
Это свойство следует из рефлексивности
:
A xA (x, x)
xA
x[x]
-
Каждый элемент из класса образует в
точности тот же самый класс.
y[x][y] = [x]
Для обоснования необходимо использовать
и свойство симметричности, и свойство
транзитивности:
y[x](y, x)& (x, y)по определению [x]и симметричности
Покажем что [y] [x],
то есть, чтоz[y]z[x]
z[y](z, y)& (y, z)по определению [y]и симметричности.
Имеем (z, y)& (y, x)
По транзитивности и определению [x]получаем (z, x) z[x]
Аналогично покажем [x] [y],
то есть, чтоz[x]z[y]
z[x](z, x)& (x, z)по определению [x]и симметричности.
Имеем (z, x)& (x, y)
По транзитивности и определению [y]получаем (z, y) z[y]
Из [y] [x]и [x] [y]получаем [y] = [x]
Следующий возможный фрагмент графа
поясняет эти 4 связи (рефлексивность
непосредственно не используется для
доказательства, но петли на графе
приведены для иллюстративных целей, – это эквивалентность):

То есть, если zэквивалентенx, аxиyэквивалентны между
собой, тоzэквивалентен
каждому из них. Фактически, класс [z]совпадет с [x]и [y].
Рассмотренное свойство можно сформулировать
и в виде следующей фразы:
-
Каждый класс эквивалентности
представляет собой в точности множество
всех своих образующих элементов.
-
Два класса либо не имеют общих
элементов, либо полностью совпадают.
Возможные формулировки:
xA yA ([x] [y] = ) ( [x] = [y] )
или
([x] [y] )([x] = [y])
([x] [y])([x] [y] = )
Таким образом, каждый класс эквивалентности
представляет собой полносвязнное по множество, а между разными классами
связейнет. Пример
фрагмента графа, удовлетворяющего этому
условию, показан на рисунке.

В множестве Aвыделено
два класса эквивалентности
[x]=[y]=[z]={x, y, z}
и [u]=[v]={u, v}.
Эти классы образуют разбиение множестваA. Это множество
(множество классов) называется
фактормножеством. Для него используется
следующее обозначение:
![]() = { [x] | xA }
= { [x] | xA }
В данном примере
![]() = {{x, y, z}, {u, v}}
= {{x, y, z}, {u, v}}
Вообще разбиением некоторого
множества A называют
семейство множеств (множество S
из множеств C),
таких, что они
-
не пустые
-
в объединении покрывают всё множество
A -
попарно либо не пересекаются, либо
полностью совпадают
(CS C)
&
![]() &
&
(C1S
C2S
((C1C2=) (C1=C2)))
При этом сами множества из семейства
называют классами разбиений.
Покажем, что любое такое разбиение
порождает некоторое отношение
эквивалентности ,
которое можно охарактеризовать как
свойство «принадлежать одному классу
разбиения»:
= {(x, y) | CS xC & yC}
Рефлексивность: xA
&![]()
CS
xC
(x, x).
Симметричность: Следует из коммутативности
связки & в определении .
Транзитивность:
(x, y)
& (y, z)
(C1S
xC1 & yC1)
& (C2S
yC2 & zC2)
(C1S
C2S
xC1 & yC1
&
yC2 & zC2
&
C1C2
& C1=C2)
(CS xC & zC)(x, z)
Важным примером отношений эквивалентности
являются отношения, получаемые при
функциональном отображении одного
множества на другое. Допустим, f BA.
Построим отношениеAAследующим образом:
= {(x, y) | f(x)=f(y) }
Тогда оно будет являться отношением
эквивалентности. Эквивалентными будут
элементы, которым функция fставит в соответствие одинаковые
значения (в смысле некоторого отношения
равенства на множествеB).
При этом классом эквивалентности будут
множества всех тех элементов вA,
для которых значения функции равны:
[x] = {y | f(x)=f(y) }
Следующая диаграмма показывает пример
такого отношения:

То, что данное отношение действительно
является эквивалентностью, непосредственно
следует из аналогичных свойств отношения
= на множестве B.
Примеры отношений
эквивалентности: Сравнимость. Конгруэнция.
В теории чисел часто рассматривается
следующее отношение эквивалентности.
По некоторому натуральному числу nлюбоецелоечислоxможно единственным образом представить
в видеx=an+bтак, чтобы 0≤bиb<n.
Тогдаbназывают
остатком от деленияxнаn. При фиксированномnbможно рассматривать в качестве результата
вычисления некоторой функции:b=Rn(x).
Определяя по рассмотренной схеме для
этой функции отношение эквивалентности,
получаем отношение «иметь одинаковые
остатки от деления наn»:n = {(x, y) | Rn(x)=Rn(y) }.
Такое отношение называетсясравнением
по модулюn. Для него
в математике используется специальное
обозначение
xy (modn)
Читается: «xсравнимо
сyпо модулюn».
Каждый класс эквивалентности для этого
отношения представляет собой множество
чисел, дающих определённый остаток от
деления на n, и называетсяклассом вычетов по модулюn.
Обозначаются эти классы обычно просто
символами квадратных скобок вокруг
числа, выбранного образующим элементом
класса. Обычно числоnясно из контекста. Образующими обычно
берут минимальные неотрицательные
элементы классов.
Пример для n=3. Возможны
три вида остатков: 0, 1, 2. Множество всех
классов вычетов по модулю 3 будет
{[0], [1], [2]}. Число 7 и число 13 оба дают
остаток от деления на 3, равный 1. Поэтому
пишут 713 (mod 3),
при этом 7[1]
и 13[1].
Множество всех целых чисел обычно
обозначают символом ℤ,
а множество всех классов вычетов по
модулюnобозначаютℤn.
Например,
ℤ3={[0], [1], [2]}.
Для операции сложения целых чисел +
такое разбиение на классы эквивалентности
обладает важным свойством:
ab (mod
n) &
cd (mod
n)
a+cb+d (mod
n)
Получается, что данное отношение
эквивалентности «согласовано» с
некоторой операцией на разбиваемом
множестве.
Отношение эквивалентности, согласованное
с некоторой ассоциативной операцией
на разбиваемом им на классы множестве,
называется конгруэнцией:
(a, b)& (c, d) (a∗c, b∗d),
где ∗–
некоторая ассоциативная бинарная
операция.
Таким же свойством сравнение по модулю
nобладает и по отношению
к умножению целых чисел:ab (modn) &cd (modn)acbd (modn).
Конгруэнция – основной способ получения
конечных алгебр (особенно недвоичных)
из бесконечных. Она позволяет определять
операции между классами на основе
операций между образующими элементами.
Операцией между классами называют
множество возможных значений результатов
операции между элементами классов:
[x]∗[y]={ u∗v | u[x] & v[y] }
Для конгруэнции имеет место следующее
представление:
[x]∗[y]=
[x∗y]
Для рассмотренного примера сравнения
по модулю 3 можно построить следующие
алгебры сложения и умножения классов:
-
+
[0]
[1]
[2]
[0]
[0]
[1]
[2]
[1]
[1]
[2]
[0]
[2]
[2]
[0]
[1]
| | [0] | [1] | [2] |
| [0] | [0] | [0] | [0] |
| [1] | [0] | [1] | [2] |
| [2] | [0] | [2] | [1] |
Такая алгебра классов с операциями + и
называется кольцом
классов вычетов по модулю 3. Например,
выражение [2]+[2]=[1] означает, что если
сложить любые два числа, дающие остаток
от деления на 3 равный 2, то получится
число, дающее остаток от деления на 3
равный 1.
Примеры отношений
эквивалентности: Эквивалентность
(равномощность) множеств. Мощность
множества. Счётные и несчётные множества.
Еще одним примером отношения
эквивалентности является уже упомянутая
эквивалентность (равномощность)
множеств: A~B(f BA ( f -1 AB)). То, что это действительно отношение
эквивалентности, следует из следующего:
-
Рефлексивность. Каждое множество
равномощно самому себе. Рассматривая
отношение Aкак функцию, ставящую каждому элементу
множестваAего
самого,A
AA,xA A(x)=x(эта функция биективная, так как
(A)-1=A)
видим, чтоA~A.
То, что некоторая функция устанавливает
равномощность, удобно обозначать,
надписывая её обозначение над символом
~:
 .
. -
Симметричность.
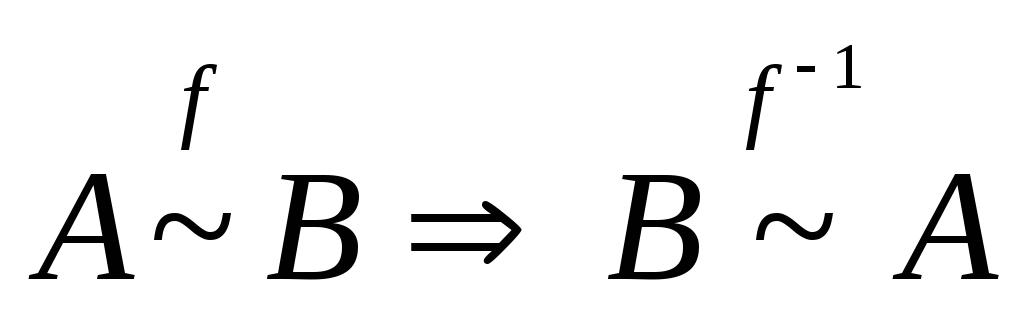 .
. -
Транзитивность.

Классы эквивалентности отношения ~
представляют собой множества из всех
множеств, равномощных некоторому
образующему элементу (множеству).
Обозначаются они обычно вертикальными
чертами с обеих сторон от выбранного
образующего элемента (множества) –
представителя класса:
|A| = { B |A~B }
Такой класс эквивалентности называют
мощностью множества. Для
конечных множеств представление о
таких классах можно считать отвлечённым
представлением о числе, возникающим
при рассматривании разнородных наборов
предметов, общим для которых является
именно количество предметов в наборах.
Для бесконечных множеств их мощности
представляют дальнейшее развитие
понятия числа.Мощности произвольных
множеств называют кардинальными
числами.Множества, равномощные
множеству натуральных чиселℕ,называют счётными множествами.В математике известны примеры построенных
определений для бесконечных множеств,
не являющихся счётными, например
множество всех функцийℬℕ(ℬ={0, 1})
не является счётным. Это множество
можно представить как множество всехбесконечныхдвоичных последовательностей.
В каждой последовательности на позиции
с номеромjℕ
записано одно из двух возможных
значений 0 или 1 (как функция от номера
позиции). Если бы всё множество таких
последовательностей было счётным
(каждой последовательности был бы
назначен номерiℕ),
последовательности можно было бы
представить в видеaij,
гдеi– номер
последовательности,j– номер позиции. Но тогда можно построить
новую последовательность, не совпадающую
ни с одной из перечисленных по формуле
jℕ bj = ajj
Эта последовательность, на каждой
позиции которой с номером jзаписано значениеbj,
отличается от всех последовательностей,
которые можно данным образом занумеровать
(от каждой занумерованной последовательности
она отличается, по крайней мере, в
позиции, равной номеру последовательности).
С другой стороны, она также (как функция
от номера позиции) является элементом
множестваℬℕ.
То есть, каково бы ни было отображение
изℕвℬℕ,
вℬℕостанутся незанумерованные элементы
(функции), что и показывает несчётностьℬℕ.
Для конечных множеств само число
элементов выбирают в качестве обозначений
их мощности, пишут |A|=n,
имея в виду, что каждому натуральному
числуnℕвзаимнооднозначно сопоставлен некоторый
класс множеств, равномощныхKn–
множеству натуральных чисел от 1 доn.
Мощность самого множестваℕтрадиционно обозначают |ℕ|=0(древнееврейская буква алеф с индексом
0, обычно произносят «алеф-ноль»,
индексирование используется для
указания порядковых типов множеств,
здесь не рассматривается). Мощность
множестваℬℕобозначают как |ℬℕ|=(алеф без индекса) или готической буквойc,
и называютмощностью континуума.
Примеры отношений
эквивалентности: подобие (изоморфизм)
бинарных отношений (ориентированных
графов).
Следующий пример связан непосредственно
с самим предметом рассмотрения –
бинарными отношениями. Допустим, задано
два бинарных отношения, каждое на своем
множестве: AAи BBи имеется биективная функция со следующим
свойством:
fBA & f -1AB & (xA yA
( (x, y) ↔ (f(x), f(y)) ) )
Следующий рисунок иллюстрирует пример
такого отображения.

Везде, где есть связь по отношению вA, есть связь между
соответствующими отображениями по
функцииfвBпо. И наоборот,
если нет связи вAмежду некоторыми элементами, то нет и
связи между их отображениями вB.
Например, (a, b),f(a)=p,f(b)=qи (p, q).
Где есть петля в графе,
есть петля в графев вершине, соответствующей вершине с
петлей впо функцииf.
Отношения, между которыми можно
установить такие отображения, называются
подобными.
Возможность установить такое отображение
называется отношением подобия. Отношение
подобия обозначим инфиксным символом
.
AA& BB&
(
f BA ( f -1 AB
) & (xA yA
( (x, y) ↔ (f(x), f(y)) ) )
Как и с равномощностью множеств, для
удобства будем надписывать над символом обозначение функции, устанавливающей
данное соответствие.
Покажем, что подобие отношений является
отношением эквивалентности.
-
Рефлексивность.

-
Симметричность.

-
Транзитивность.

Классы эквивалентностей отношения
подобия представляют собой множество
всех отношений, имеющих определенную
структуру связей между элементами без
учета названий элементов и отношений.
С точки зрения рассмотрения графов
подобных отношений, подобие – это
свойство иметь одинаковую форму графа.
В рассмотренном примере оба графа могут
быть описаны словами «три вершины, одна
стрелка и петля в вершине, куда входит
стрелка». Такие классы эквивалентностей
можно назвать абстрактными отношениями.
Их можно изображать графами, не подписывая
узлов. Важно, что все свойства отношений,
рассматриваемые здесь, не зависят от
названий отношений, названий элементов
и интерпретации отношения в предметной
области. С другой стороны, изучив
свойства какого-либо конкретного
отношения, фактически мы изучили
свойствавсехотношений данного
класса. Для рассмотренного примера
граф абстрактного отношения выглядит
так:

Число различных классов отношений
вообще-то меньше, чем самих отношений.
Например, для двоичного множества все
отношения могут быть представлены
логическими матрицами 22.
Таких матриц 16. Некоторые из них будут
представлять подобные отношения.
Разбиение множества таких матриц на
классы эквивалентности по подобию
соответствующих им отношений представим
ориентированными графами и укажем
матрицы, реализующие эти отношения.
Видно, что число классов (форм конфигураций
связей) будет 10. Некоторые классы имеют
по две реализации.









В этой статье мы разберем одну из самых известных и фундаментальных техник, технику выделения классов эквивалентности и граничных значений.
В чем суть техники?
Основная задача определения классов эквивалентности и граничных значений — «уйти» от дублирующих проверок. Таким образом, мы сократим количество однотипных тестов до необходимого минимума. Как это можно представить?
Предположим, у нас много-много разных булок, сделаны они по одному рецепту, а вот форма у них немного разная. А теперь представьте, что вам необходимо определить вкус каждой булки. Что вы будете делать? Попробуете все или возьмете только одну, потому что остальные сделаны аналогично? Я думаю второй вариант будет более оптимальным)
В тестировании ситуация аналогичная. Только вместо булок наши тесты. И все немного сложнее.
Классы эквивалентности
Сначала дадим определение классам эквивалентности.
Эквивалентная область (equivalence partition) —часть области входных или выходных данных, для которой поведение компонента или системы, основываясь на спецификации, считается одинаковым.
Скорей всего было не очень понятно…

Проще говоря, любой тест, выполненный из одного и того же класса эквивалентности, приведет к точно такому же результату, как и выполнение всех остальные тестов из этого же класса.
Например, у нас есть 10 тестов из одного класса. Если один из этих тестов проходит корректно, и то все остальные пройдут корректно. И наоборот, если один из тестов приведет к падению системы, то и все остальные тесты, также приведут к падению.
Пока все еще абстрактно, давайте конкретизируем. Предположим, у нас планируется акция «Скидка 10% на покупку от 5 товаров». Нам необходимо проверить функционал скидки в зависимости от количества товаров. Что будем делать? Есть два варианта проверки:
- Проверить, что скидки нет при покупке 1-го, 2-х, 3-х и 4-х товаров, начиная с 5 и так далее скидка в 10%. Т.е. на каждое число товаров проводить 1 тест.

Тестов получается очень много.
2. Попробовать выделить классы эквивалентности и оптимизировать проверки.
Пойдем по второму варианту, он более эффективный. У нас всего два разных результата выполнения теста — со скидкой и без скидки. Логично предположить, что класса эквивалентности тоже будет два. В одном тесты будут проверять наличие скидки в 10%, в другом ее отсутствие.
Графически это можно представить следующим образом:

Т.е. какой бы мы тест не взяли из первого класса, мы получим скидку в 0%, аналогично для второго класса эквивалентности.
Теперь теория и здравый смысл подсказывают нам, что можно взять не все тесты, а только несколько из каждого класса эквивалентности. Этого должно быть достаточно, чтобы проверить оба случая со скидкой.
Но теперь вопрос, какие тесты брать? Есть ли разница между ними, может быть все-таки есть небольшие отличия?
Граничные значения
Путем долгого времени наблюдения за разработкой и анализа багов, специалисты пришли к выводу, что большинство ошибок возникает именно на границах между классами эквивалентности. Т.е. нам в первую очередь важно проверить переходы на стыке границ каждого класса, так как именно там велик риск возникновения ошибок.
Поэтому для эффективного тестирования нам необходимо выделить у каждого класса граничные значения. Давайте попробуем сделать на нашем примере:
- Скидка 0% действует при покупке от 1 до 4 товаров, следовательно будут два граничных значения: 1 и 4.
- Скидка 10 % действует при покупке от 5 товаров и выше, т.е. граничное значения для второго будет — 5. По поводу второй границы класса необходимо смотреть в реализацию, она должна быть равна максимальному числу товаров, которое можно положить в корзину. Чтобы не усложнять себе работу, возьмем максимальное число товаров — 100.
- Таким образом, мы с вами определили верхнюю и нижнюю границу каждого класса. Эти значения мы и возьмем в тестирование. Получаем таблицу:

Итого, 4 теста вместо 100 с учетом сохранения тестового покрытия.
Наша задача, как тестировщика, уметь правильно определить и работать с классами эквивалентности и граничными значениями. Выше мы рассмотрели пример с позиции черного ящика. У него есть существенные минус, мы не знаем как реализована работа функционала с точки зрения кода. Следовательно, не можем со 100% уверенностью правильно выделить классы эквивалентности.
Давайте рассмотрим пример посложней. Нам необходимо проверить корректность бокового меню на сайте из 10 страниц. Вот такое:
Страницы сами по себе одинаковые и отличаются только содержанием, боковое меню зрительно полностью идентично.
Только что пройденный материал подсказывает нам, что есть один класс эквивалентности и он включает в себя все 10 страниц. Но на практике есть как минимум два варианта:
1. Если сайт сделан на HTML, в том числе и боковое меню, то необходимо проверять КАЖДУЮ страницу, так как на каждой странице боковое меню работает отдельно от остальных.
2. Если сайт сделан с помощью, например, шаблонизаторов, то тогда выделить 10 страниц в класс эквивалентности можно, так как код меню хранится отдельно.
Т.е. в зависимости от реализации, классы будут разные. Как это определить? Если вы знаете языки программирования и у вас есть доступ в репозиторий, то посмотреть в код. Если вы не поняли, что я сейчас написал, то подойдет и второй вариант) Поговорите с программистом, который делал эту функциональность и уточните у него, правильно ли вы делаете.
Содержание
- Что это
- Особенности
- Типы
- Советы
- Примеры
- Преимущества/недостатки
- Стандартные действия
- Чем отличается от анализа граничных значений
Коротко: выбранные тестировщиком наборы данных (диапазоны), которые подаются на ввод в модуль, и это должно приводить к одинаковым результатам.
Методика группировки и разделения тестовых входных данных на некие эквивалентные классы. Широко применяемая техника тестирования черного ящика; относится к базовым; всегда спрашивают на собеседованиях. Альтернативное название: эквивалентное разбиение.
Как гласит Первый принцип тестирования, “полное тестирование программы невозможно, или займет недопустимо длительное время”. Причина в том, что нужно проверить слишком много комбинаций тестовых данных.
Например, слушатель курсов программирования написал простейший калькулятор, и нужно протестировать в нем (хотя бы) все возможные операции сложения (а их 10 в 16 степени, то есть 10 квадриллионов), на это понадобятся миллиарды лет.
Классы эквивалентности помогают тестировщику получить четкие результаты за ограниченное время, покрывая множество тестовых сценариев. Улучшается качество тест-кейсов, устраняется избыточность, возможная в других методиках.
Особенности
- Это методика черного ящика (то есть тестировщик не видит код, является “внешним наблюдателем” по отношению к программе)
- Еще одна формулировка КЭ: формируются группы (классы) тестовых вводов с одинаковым поведением
- Суть в том, что если один член класса ведет себя каким-то образом, то и все остальные члены должны вести себя так же
- Применяется на любом этапе жизненного цикла тестирования
- В том числе в юнит-тестировании, интеграционном, системном и приемочном тестировании
- Тест-кейсы основаны на классах (а не на отдельных тестовых вводах, которых может быть огромное количество). Это экономит рабочее время, потому как не создается много избыточных тест-кейсов.
- Техника применяется, когда тестовые данные можно поделить на интервалы и наборы дискретных значений (то есть почти всегда)
- Как правило, в QA применяется сочетание классов эквивалентности и граничных значений — это дает более надежные результаты.
Стандартные действия по методике
- Правильно определяются классы эквивалентности, это главное.
- Выбирается один представитель (член) в каждом классе. Из каждого эквивалентного набора тестов выбирается один тест.
- Выполнение тестов от каждого класса.
- Если времени достаточно (или ситуация требует, см. далее о типах), берутся несколько членов из каждого класса. Но у опытного тестировщика классы определены правильно с начала, поэтому несколько членов будут не обязательны (избыточны = покажут те же результаты).
Пример
Есть приложение, принимающее на ввод число из 2 или 3 цифр. Из условия понятно, что диапазон возможных чисел — достаточно большой, и все варианты проверить получается неэкономно.
- Теперь эти числа группируем, формируя из них классы эквивалентности. Вместо проверки сотен чисел сформируем из них 4 эквивалентных класса, и разделим вводы на категорию валидных и невалидных.
- Один элемент из класса как бы представляет весь класс. Например, число 122 представляет класс “трехзначные числа”. Поданное на ввод, число 122 не вызывает ошибку в приложении (тест пройден). Из этого делаем вывод, что все другие члены класса “Трехзначные” также будут нормально приняты приложением. А если тест не пройдет с числом 122, то предполагается, что все трехзначные числа будут вызывать ошибку.
- А теперь берем число 7 из класса “однозначные числа”, то есть невалидный ввод. Ожидается, что приложение выдаст ошибку в ответ на заведомо невалидный ввод, и это будет значить, что оно работает правильно, и предполагается, что остальные однозначные числа также будут вызывать ошибку.
Еще пример
Есть приложение, в которое подается число от 10 до 100, и затем вычисляется его корень. Эквивалентные классы будут такими:
| Класс | Описание |
|---|---|
| Числа от 10 до 100 | Дата-сет для позитивного сценария |
| Числа от 0 до 9 | Дата-сет для негативного сценария |
| Числа больше 100 | Тоже не примет приложение |
| Отрицательные числа | Усложняем задачу |
| Буквы | Еще усложняем |
| Специальные символы типа %^&# | И еще такой отдельный класс |
Типы классов эквивалентности ( * )
- Weak Normal. Тестируется по одной переменной из каждого класса. Поэтому еще называется предположением об одной ошибке (single fault assumption)
- Strong Normal, или предположение о нескольких ошибках. Создаются тест-кейсы из каждого элемента в множестве прямого произведения эквивалентности. Это улучшает охват тестирования, поскольку покрывает все возможные классы, позволяя проверить все возможные комбинации вводов.
- Weak Robust, как и Weak Normal, тестирует одну переменную из каждого КЭ, но фокусируется на тест-кейсах с невалидными значениями.
- Strong Robust. Создаются тест-кейсы для всех валидных и невалидных элементов произведения эквивалентного класса. Это “неэкономный” тип КЭ, не уменьшающий избыточность тест-кейсов.
Советы
- Robust-типы применяются, если условия ошибки являются высокоприоритетными для проверки, и в сложных функциях
- Robust применяется, если невалидные значения вызывают runtime-ошибки в системе (в языках со строгой типизацией)
- Берутся одно валидное и оно невалидное значение, если входные условия в приложении не очень ясны
- Установление правильной эквивалентности может требовать опыта, и усилий
- Чем больше создано классов, тем вероятнее, что много тестов окажутся избыточными
- И чем меньше классов, тем выше вероятность пропуска ошибок
Преимущества и недостатки
Плюсы
- Главное — уменьшает количество тест-кейсов, не уменьшая покрытие
- Уменьшает время тестирования и упрощает процесс, меньше данных обрабатывается
- Применяется на всех этапах и уровнях тестирования
- Позволяет сфокусироваться на небольших наборах данных, что улучшает вероятность найти больше багов
- Тесты получаются более структурированными
- Подходит для проектов с ограничением времени и ресурсов (то есть всегда)
Минусы
- Не учитывает условия по граничным значениям (поэтому надо сочетать с анализом граничных значений)
- Подбор эквивалентных классов — сложная вещь для новичков
Разница между классами эквивалентности и анализом граничных значений
| Классы эквивалентности | Граничные значения |
|---|---|
| Стандартная техника «черного ящика», с которой начинают тестирование | Часто последующий этап «черного ящика», продолжение тестирования после эквивалентных классов |
| Применяется на любом этапе тестирования: юнит-, интеграционное, системное, и пр. | Как дополнение к КЭ и как часть негативного или стресс-тестирования |
| Техника: тестовые данные делятся на эквивалентные классы, которые “должны вести себя одинаково” | Техника: проверяются “значения на границах” классов |
| Экономит время на тестирование, меньше тест-кейсов и они более эффективные | Уменьшает общее время выполнения тестов, делая поиск багов быстрее и проще |
| Стандартно тестируется только по одному значению из каждого эквивалентного класса | Тест-кейсы создаются из граничных значений классов |
| Альтернативное название: эквивалентное разбиение | Альтернативное название: проверка границ диапазона |
Анализ классов эквивалентности
В учебных программах по дисциплине «Обеспечение качества и тестирование программ» есть тема для изучения — «Техники тестирования. Метод эквивалентных классов и граничных значений».
В программе обучения базового уровня International Software Testing Qualifications Board «Сертифицированный тестировщик» указано на необходимость:
- Создать тестовые сценарии для приведенных моделей программного обеспечения при помощи следующих методов проектирования тестов: (1) эквивалентное разбиение; (2) анализ граничных значений; (3) тестирование таблицы решений; (4) тестирование таблицы переходов.
- Объяснить назначение каждого из четырех методов, какие уровни и типы тестирования могут использовать данные методы, и каким образом может быть измерено покрытие при использовании данных методов.
Содержание:
- «Искусство тестирования программ», Глендфорд Майерс
- «Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений», Сэм Канер, Джек Фолк и Енг Кек Нгуен
- «Тестирование черного ящика. Технологии функционального тестирования программного обеспечения систем», Борис Бейзер
- «Тестирование Дот Ком, или Пособие по жестокому обращению с багами в интернет-стартапах», Роман Савин
- «Тестирование программного обеспечения. Базовый курс», Святослав Куликов
«Искусство тестирования программ», Глендфорд Майерс
Москва, Финансы и статистика, 1982 год. 63-74 страницы:
Эквивалентное разбиение
В главе 2 отмечалось, что хороший тест имеет приемлемую вероятность обнаружения ошибки и что исчерпывающее входное тестирование программы невозможно. Следовательно, тестирование программы ограничивается использованием небольшого подмножества всех возможных входных данных. Тогда, конечно, хотелось бы выбрать для тестирования самое подходящее подмножество (то есть подмножество с наивысшей вероятностью обнаружения большинства ошибок).
Правильно выбранный тест этого подмножества должен обладать двумя свойствами:
- уменьшать, причем более чем на единицу, число других тестов, которые должны быть разработаны для достижения заранее определенной цели «приемлемого тестирования»;
- покрывать значительную часть других возможных тестов, что в некоторой степени свидетельствует о наличии или отсутствии ошибок до и после применения этого ограниченного множества значений входных данных.
Указанные свойства, несмотря на их кажущееся подобие, описывают два различных положения. Во-первых, каждый тест должен включать столько различных входных условий, сколько это возможно, с тем чтобы минимизировать общее число необходимых тестов. Во вторых, необходимо пытаться разбить входную область программы на конечное число классов эквивалентности так, чтобы можно было предположить (конечно, не абсолютно уверенно), что каждый тест, являющийся представителем некоторого класса, эквивалентен любому другому тесту этого класса.
Иными словами, если один тест класса эквивалентности обнаруживают ошибку, то следует ожидать, что и все другие тесты этого класса эквивалентности будут обнаруживать ту же самую ошибку. Наоборот, если тест не обнаруживает ошибки, то следует ожидать, что ни один тест этого класса эквивалентности не будет обнаруживать ошибки (в том случае, когда некоторое подмножество класса эквивалентности не попадает в пределы любого другого класса эквивалентности, так как классы эквивалентности могут пересекаться).
Эти два положения составляют основу методологии тестирования по принципу чёрного ящика, известной как эквивалентное разбиение. Второе положение используется для разработки набора «интересных» условий, которые должны быть протестированная, а первое – для разработки минимального набора тестов, покрывающих эти условия.
Примером класса эквивалентности для программы о треугольнике (смотри главу 1) является набор «трёх равных чисел, имеющих целые значения, большие нуля». Определяя этот набор как класс эквивалентности, устанавливают, что если ошибка не обнаружена некоторым тестом данного набора, то маловероятно, что она будет обнаружена другим тестом набора. Иными словами, в этом случае время тестирования лучше затратить на что-нибудь другое (на тестирование других классов эквивалентности).
Разработка тестов методом эквивалентного разбиения осуществляется в два этапа:
- выделение классов эквивалентности и
- построение тестов.
Выделение классов эквивалентности
Классы эквивалентности выделяются путем выбора каждого входного условия (обычно это предложение или фраза в спецификации) и разбиением его на две или более групп. Для проведения этой операции используют таблицу, изображенную на рисунке 4.3. Заметим, что различают два типа классов эквивалентности: правильные классы эквивалентности, представляющие правильные входные данные программы, и неправильные классы эквивалентности, представляющие все другие возможные состояния условий (то есть ошибочные входные значения). Таким образом, придерживаются одного из принципов главы 2 о необходимости сосредоточивать внимание не неправильных или неожиданных условиях.
| Входные условия | Правильные классы эквивалентности | Неправильные классы эквивалентности |
|---|---|---|
| … | … | … |
Если задаться входными или внешними условиями, то выделение классов эквивалентности представляет собой в значительной степени эвристический процесс (под эвристикой понимают совокупность приёмов и методов, облегчающих и упрощающих решение познавательных, конструктивных, практических задач). При этом существует ряд правил:
- Если входное условие описывает область значений (например, «целое данное может принимать значения от 1 до 999»), то определяются один правильный класс эквивалентности (1 <= значение целого данного <= 999) и два неправильных (значение целого данного < 1 и значение целого данного > 999).
- Если входное условие описывает число значений (например, «в автомобиле могут ехать от одного до шести человек»), то определяются один правильный класс эквивалентности и два неправильных (ни одного и более шести человек).
- Если входное условие описывает множество входных значений и есть основание полагать, что каждое значение программа трактует особо (например, «известны способы передвижения на АВТОБУСЕ, ГРУЗОВИКЕ, ТАКСИ, ПЕШКОМ или МОТОЦИКЛЕ»), то определяется правильный класс эквивалентности для каждого значения и один неправильный класс эквивалентности (например, «НА ПРИЦЕПЕ»).
- Если входное условие описывает ситуацию «должно быть» (например, «первым символом идентификатора должна быть буква), то определяется один правильный класс эквивалентности (первый символ – буква) и один неправильный (первый символ – не буква).
- Если есть любое основание считать, что различные элементы класса эквивалентности трактуются программой неодинаково, то данный класс эквивалентности разбивается на меньшие классы эквивалентности.
Этот процесс ниже будет кратко проиллюстрирован.
Построение тестов
Второй шаг заключается в использовании классов эквивалентности для построения тестов. Этот процесс включает в себя:
- Назначение каждому классу эквивалентности уникального номера.
- Проектирование новых тестов, каждый из которых покрывает как можно большее число непокрытых правильных классов эквивалентности, до тех пор пока все правильные класс эквивалентности не будут покрыты (только не общими) тестами.
- Запись тестов, каждый из которых покрывает один и только один из непокрытых неправильных классов эквивалентности, до тех пор пока всех неправильные классы эквивалентности не будут покрыты тестами.
Причина покрытия неправильных классов эквивалентности индивидуальными тестами состоит в том, что определённые проверки с ошибочными входами скрывают или заменяют другие проверки с ошибочными входами.
Например спецификация устанавливает «тип книги при поиске (ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА, ПРОГРАММИРОВАНИЕ или ОБЩИЙ») и количество (1-9999)». Тогда тест
отображает два ошибочных условия (неправильный тип книги и количество) и, вероятно, не будет осуществлять проверку количества, так как программа может ответить: «XYZ — НЕСУЩЕСТВУЮЩИЙ ТИП КНИГИ» и не проверять остальную часть входных данных.
Пример
Предположим, что при разработке компилятора для подмножества языка Фортран требуется протестировать синтаксическую проверку оператора DIMENSION. Спецификация приведена ниже. (Этот оператор не является полным оператором DIMENSION Фортрана; спецификация была значительно сокращена, что позволило сделать ее «учебным примером». Не следует думать, что тестирование реальных программ так же легко, как в примерах данной книги.) В спецификации элементы, написанные латинскими буквами, обозначают синтаксические единицы, которые в реальных операторах должны быть заменены соответствующими значениями, в квадратные скобки заключены необязательные элементы, многоточие показыает, что предшествующий ему элемент может быть повторен подряд несколько раз.
Оператор DIMENSION используется для определения массивов. Форма оператора DIMENSION:
где ad есть описатель массива в форме
n — символическое имя массива, а d — индекс массива. Символические имена могут содержать от одного до шести символов — букв или цифр, причем первой должна быть буква. Допускается от одного до семи индексов. Форма индекса
где lb и ub задают нижнюю и верхнюю границы индекса массива.
Граница может быть либо константой, принимающей значения от -65534 до 65535, либо целой переменной (без индексов). Если lb не определена, то предполагаетя, что она равна единице. Значение ub должно быть больше или равно lb. Если lb опрееделена, то она может иметь отрицательное, нулевое или положительное значение. Как и все операторы, оператор DIMENSION может быть продолжен на нескольких строках. (Конец спецификации.)
Первый шаг заключается в том, чтобы идентифицировать входные условия и по ним определить классы эквивалентности (таблица 4.1). Классы эквивалентности в таблице обозначены числами.
| Входные условия | Правильные классы эквивалентности | Неправильные классы эквивалентности |
|---|---|---|
| Число описателей массивов | один (1), > одного (2) | ни одного (3) |
| Длина имени массива | 1-6 (4) | 0 (5), > 6 (6) |
| Имя массива | имеет в своем составе буквы (7) и цифры (8) | содержит что-то еще (9) |
| Имя массива начинается с буквы | да (10) | нет (11) |
| Число индексов | 1-7 (12) | 0 (13), > 7 (14) |
| Верхняя граница | константа (15), целая переменная (16) | имя элемента массива (17), что-то иное (18) |
| Имя целой переменной | имеет в своем составе буквы (19), и цифры (20) | состоит из чего-то еще (21) |
| Целая переменная начинается с буквы | да (22) | нет (23) |
| Константа | -65534-65535 (24) | < -65534 (25), > 65535 (26) |
| Нижняя граница определена | да (27), нет (28) | |
| Верхняя граница по отношению к нижней границе | больше (29), равна (30) | меньше (31) |
| Значение нижней границы | отрицательное (32), нуль (33), > 0 (34) | |
| Нижняя граница | константа (35), целая переменная (36) | имя элемента массива (37), что-то иное (38) |
| Оператор расположен на нескольких строках | да (39), нет (40) |
Следующий шаг — построение теста, покрывающего один или более правильных классов эквивалентности. Например, тест
покрывает классы 1, 4, 7, 10, 12, 15, 24, 28, 29 и 40. Далее определяются один или более тестов, покрывающих оставшиеся правильные классы эквивалентности. Так, тест
DIMENSION A12345(I,9,J4XXXX,65535,1,KLM, X 100), BBB (-65534:100,0:1000,10:10,1:65535)
покрывает оставшиеся классы. Перечислим неправильные классы эквивалентности и соответствующие им тесты:
(3): DIMENSION
(5): DIMENSION (10)
(6): DIMENSION A234567(2)
(9): DIMENSION A.1(2)
(11): DIMENSION 1A(10)
(13): DIMENSION B
(14): DIMENSION B(4,4,4,4,4,4,4,4)
(17): DIMENSION B(4,A(2))
(18): DIMENSION B(4,,7)
(21): DIMENSION C(I.,10)
(23): DIMENSION C(10,1J)
(25): DIMENSION D(-65535:1)
(26): DIMENSION D(65536)
(31): DIMENSION D(4:3)
(37): DIMENSION D(A(2):4)
(38): DIMENSION D(.:4)
Эти классы эквивалентности покрываются 18 тестами. Читатель может при желании сравнить данные тесты с набором тестов, полученным каким-либо специальным методом.
Хотя эквивалентное разбиение значительно лучше случайного выбора тестов, оно все же имеет недостатки (то есть пропускает определенные типы высокоэффективных тестов). Следующие два метода — анализ граничных значений и использование функциональных диаграмм (диаграмм причинно-следственных связей cause-effect graphing) — свободны от многих недостатков, присущих эквивалентному разбиению.
«Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений», Сэм Канер, Джек Фолк и Енг Кек Нгуен
Москва, ДиаСофт, 2001. 97, 181, 191-192 страницы:
Простейшими граничными условиями являются числовые… Любой аспект работы программы, к которому применимы понятия больше или меньше, раньше или позже, первый или последний, короче или длиннее, обязательно должен быть проверен на границах диапазона… на границах порой случаются самые неожиданные отклонения…
Весь продукт тестировать не нужно, достаточно выбрать пять полей ввода данных — они обычно имеются в любой программе… Для каждого поля ввода данных выполните следующее:
- Проанализируйте значения, которые в него можно вводить. Сгруппируйте их в классы.
- Проанализируйте возможные граничные условия. Их можно описать, исходя из определений классов, но возможно, что в ходе этого анализа добавятся и новые классы значений.
- Нарисуйте таблицу, в которой перечислите все классы значений для каждого поля ввода и все интересные тестовые примеры (граничные и другие особые значения). Пример такой таблицы приведен на рисунке 7.1. Если у вас будет плохо получаться, прочитайте раздел главы 12 «Таблицы граничных значений».
- Протестируйте программу, используя записанные значения (а если их слишком много, то некоторое их подмножество). Протестировать программу, означает не только запустить ее, ввести данные и посмотреть, не произойдет ли сбой, — важно, чтобы программа правильно использовала введенные данные. Получаются ли, например, при печати указанные пользователем отступы? Обязательно продумайте тестовую процедуру, в которой программа использует введенную вами информацию
«Быстрое тестирование», Роберт Калбертсон, Крис Браун, Гэри Кобб
Издательский дом «Вильямс», 2002 год. 75, 108-109, 214-215 страница:
Разбиение на классы эквивалентности
Разбиение на классы эквивалентности представляет собой технологию проектирования тестов, ориентированную на снижение общего числа тестов, необходимых для подтверждения корректности функциональных возможностей программы. Основная идея, стоящая за разбиением на классы эквивалентности, заключается в том, чтобы разбить область ввода программы на классы данных. Если проектировать тесты для каждого класса данных, но не для каждого члена класса, то общее количество требуемых тестов уменьшается.
В качестве примера рассмотрим программу отображения почтовых индексов, которая рассматривалась ранее в главе. Предположим, что когда пользователь вводит пятизначный почтовый индекс и общую массу отправляемого груза в унциях, программа возвращает стоимость доставки пакета. Областью ввода для этой программы являются почтовые индексы и масса брутто отправляемого груза. Область ввода почтового кода может быть разбита на класс допустимых вводов и класс недопустимых вводов следующим образом:
- Допустимыми вводами являются все пятизначные наборы цифровых символов, образующих рабочий почтовый код
- Недопустимыми вводами являются:
- Наборы цифровых символов, содержащие менее пяти символов
- Наборы цифровых символов, содержащие более пяти символов
- Наборы из пяти символов, не являющиеся рабочим почтовым кодом
- Наборы из нецифровых символов.
Аналогичное разбиение может быть построено и для массы брутто отправляемого груза. Например, требуется программа, работающая только с грузами, масса которых находится в диапазоне от 1 до 100 унций. В этом случае числовые значения, попадающие в диапазон от 1 до 100, включая и конечные точки, являются допустимыми. Все значения меньше 1 и больше 100, отрицательные значения и нецифровые значения образуют недопустимые классы ввода.
Нужно спроектировать такие тесты, которые выполняют проверку, по меньшей мере, одного представителя каждого допустимого класса ввода и, по меньшей мере, одного представителя недопустимого класса ввода. В результате тестирования с применением допустимых вводов должны быть получены однозначно определенные и ожидаемые результаты. Для почтового кода 78723 и массы в 20 унций ожидается получить конкретное значение стоимости, и это значение должно быть определено в функциональных требованиях. В случае ввода недопустимых данных должно быть получено соответствующее сообщение об ошибке, если оно определено в технических требованиях и спецификациях. При вводе недопустимых данных программа, по меньшей мере, не должна завершаться аварийно, вызывать искажение данных или вести себя непредсказуемым образом.
Более подробное обсуждение разбиения на классы эквивалентности можно найти в главе 10 «Технологии динамического тестирования и советы», а также в:
- Myers, Glen. (1979). The Art of Software Testing. New York: Wiley.
- Kaner, Cem, Jack Falk, and Hung Quoc Nguyen. (1999). Testing Computer Software (2nd ed.). New York: Wiley.
- Pressman, Roger. (1997). Software Engineering: A Practitioner’s Approach (4th ed.). New York: McGraw-Hill.
- Kit, Edward. (1995). Software Testing in the Real World: Improving the Process. Reading, MA: Addison-Wesley.
- Fewster, Mark, and Dorothy Graham. (1999). Software Test Automation. Reading, MA: Addison-Wesley.
Разделение по классам эквивалентности
Принадлежность двух элементов данных к одному и тому же классу эквивалентности просто означает, что с каждым из них функция выполняет одни и те же операции. Принадлежность двух элементов данных к различным классам эквивалентности означает, что существует, по меньшей мере, одна строка кода, требуемая для обработки одного элемента данных, которая не будет использоваться при обработке другого элемента данных. Часто данные, принадлежащие к одному из двух классов эквивалентности, называют правильными данными, а данные второго класса эквивалентности неправильными данными для данной функции. Ветви кода, которые используются для обработки правильных данных, называются удачными ветвями, в то время как ветви, выполняемые функцией при обработке неправильных данных, называются неудачными ветвями. В проектной документации для большинства функций определены правильные и неправильные входные данные. Для определения классов эквивалентности данных для каждой функции тестировщики должны прочесть проектную документацию. Если эта информация отсутствует в проектной документации, тестировщику придется применить функциональный анализ и восстановить информацию о классах эквивалентности снизу-вверх. В некоторых случаях в проектной документации может использоваться также термин допустимых и недопустимых данных для дайной функции. Операции тестирования во время ввода неправильных данных достаточно точно называются отрицательным тестированием. Неправильные данные выбираются с тем, чтобы убедиться в наличии в каждой функции обработчиков исключений, выполняющих обработку неправильных данных. Отрицательное тестирование не ограничивается одним лишь выполнением операций тестирования для случая неправильных данных (обратитесь к разделу, посвященному отрицательному тестированию, далее в этой главе).
Одна из принципиальных отличительных черт специалиста по тестированию, применяющего технологии быстрого тестирования, состоит в том, что при оценке вероятности наличия скрытых ошибок, которые могут препятствовать эффективному использованию конечной программы, он всегда учитывает широту и степень покрытия тестирования. Чтобы гарантировать тестирование как удачных, так и неудачных ветвей внутри каждой функции, тестировщик должен уделять пристальное внимание классам эквивалентности входных данных функций.
«Тестирование черного ящика. Технологии функционального тестирования программного обеспечения систем», Борис Бейзер
СПб: Питер, 2004, 55/321 страницы:
2.4.5. Классы эквивалентности и разбиения
Отношения эквивалентности — симметрично, транзитивно и рефлексивно. Набор объектов, удовлетворяющих отношению эквивалентности, называется классом эквивалентности. Каждый объект из этого класса называется эквивалентным (в смысле данного отношения) любому другому объекту этого класса.
Все методы, описываемые в этой книге, являются примерами тестирования путем разбиения:
- «Partition Testing Does Not Inspire Confidence», Hamlet R., Taylor R, 1988.
- «The Category-Partition Method for Specifying and Generating Fenctional Tests», Ostrand T.J., Baker M.J., 1998.
- «A Partition Analysis Method to Increase Program Reliability», Richardson D.J., Clarke L.A., 1981.
- «Approaches to Specification-Based Testing», Richardson D.J., 1989.
- «Intergration Testing», White Lee J., Leung Hareton K.N., 1994.
Эта стратегия построена на разбиении всех возможных входов на классы эквивалентности по какому-либо отношению эквивалентности. Я не буду в этой книге рассказывать, как создавать или находить подобные отношения, а познакомлю вас с набором уже готовых полезных отношений и, следовательно, полезных разбиений на классы эквивалентности.
Если у вас есть транзитивное отношение, то вы можете автоматически конвертировать его в соответствующее отношение эквивалентности и таким образом разбить множество вводов на классы эквивалентности. Однако этот метод не рассматривается в данной книге. Дополнительную информацию вы найдете в главе 12 «Software System Testing and Quality Assurance» Boris Beizer, 1990.
«Тестирование Дот Ком, или Пособие по жестокому обращению с багами в интернет-стартапах», Роман Савин
Москва, Дело, 2007 год. 195-202 страницы:
Эквивалентные классы (equivalent classes)
Это суперполезная вещь, которой мы немедленно дадим определение: эквивалентный класс — это одно или больше значений ввода, к которым ПО применяет одинаковую логику.
Предположим, что наш книготорговый веб-сайт запускает новую кампанию «Больше тратишь — больше скидка». Вот табличка из спека.
| Потраченная сумма, руб. | Скидка, % |
|---|---|
| 200 — 500 | 2 |
| 500 — 1000 | 3 |
| 1000 — 5000 | 4 |
| 5000 и более | 5 |
Мы, конечно, сразу увидели 3 бага спека:
Баг1:
Непонятно, по какой ставке рассчитывается скидка, если потрачены следующие суммы: ровно 500 руб., ровно 1000 руб., ровно 5000 руб., так как каждая из этих сумм находится не в одной, а в двух корзинах со скидками.
Баг 2:
Что означает «Потраченная сумма»? Это количество дензнаков, выплаченных только за книги, или полная сумма к оплате, включая оплату книг и расходы на доставку?
Баг 3:
Для полноты картины нужно дописать эквивалентный класс от 0 до 199,99, на значения которого никакая скидка не распространяется.
Что делаем? Правильно: идем к продюсеру. Извещаем о баге программиста. «Размораживаем» спек. Вносим в него изменения.
Вот перед нами уже отредактированная табличка:
| Стоимость купленных книг, руб. | Скидка, % |
|---|---|
| 0—199,99 | 0 |
| 200,00 — 499,99 | 2 |
| 500,00 — 999,99 | 3 |
| 1000,00 — 4999,99 | 4 |
| 5000,00 и более | 5 |
У нас получилось 5 эквивалентных классов:
| Класс | Стоимость |
|---|---|
| Класс 1: | 0—199,99 |
| Класс 2: | 200,00 — 499,99 |
| Класс 3: | 500,00 — 999,99 |
| Класс 4: | 1000,00 — 4999,99 |
| Класс 5: | 5000,00 и более |
Каждое значение внутри каждого класса является эквивалентным всем другим значениям этого класса. Почему? Потому что ко всем значениям класса должна применяться одинаковая логика кода. Например, при стоимости купленных книг и 1215,11 руб., и 1745,45 руб., и 2000 руб. (класс 4) полагается скидка 4%.
Составными частями класса являются:
- Значение или корзина значений ввода (например, от500,00 до 999,99) и
- Логика для вывода, т.е. ожидаемого результата (скидка 3% в случае с классом 3).
Польза раскладывания значений ввода на эквивалентные классы состоит в том, что мы отсеиваем огромное количество значений ввода, использовать которые для тестирования просто бессмысленно.
«Тестирование программного обеспечения. Базовый курс», Святослав Куликов
Версия книги 1.2.1 от 02.08.2017, EPAM Systems. 231-236 страницы:
«An equivalence class consists of a set of data that is treated the same by a module or that should produce the same result», Lee Copeland, «A practitioner’s guide to software test design».
Класс эквивалентности — набор данных, обрабатываемых одинаковым образом и приводящих к одинаковому результату.
В качестве пояснения идеи рассмотрим тривиальный пример. Допустим, нам нужно протестировать функцию, которая определяет, корректное или некорректное имя ввёл пользователь при регистрации.
Требования к имени пользователя таковы:
- От трёх до двадцати символов включительно.
- Допускаются цифры, знак подчёркивания, буквы английского алфавита в верхнем и нижнем регистрах.
Если попытаться решить задачу «в лоб», нам для позитивного тестирования придётся перебрать все комбинации допустимых символов длиной [3, 20] (это 18-разрядное 63-ричное число, т.е. 2.4441614509104E+32). А негативных тест-кейсов здесь и вовсе будет бесконечное количество, ведь мы можем проверить строку длиной в 21 символ, 100, 10000, миллион, миллиард и т.д.
Представим графически классы эквивалентности относительно требований к длине (см. рисунок 2.7.a).
Поскольку для длины строки невозможны дробные и отрицательные значения, мы видим три недостижимых области, которые можно исключить, и получаем окончательный вариант (см. рисунок 2.7.b).
Мы получили три класса эквивалентности:
- [0, 2] — недопустимая длина;
- [3, 20] — допустимая длина;
- [21, ∞] — недопустимая длина.
Обратите внимание, что области значений [0, 2] и [21, ∞] относятся к разным классам эквивалентности, т.к. принадлежность длины строки к этим диапазонам проверяется отдельными условиями на уровне кода программы.
…
04.09.2016. Перейти на Главную страницу